What Is Data Masking?
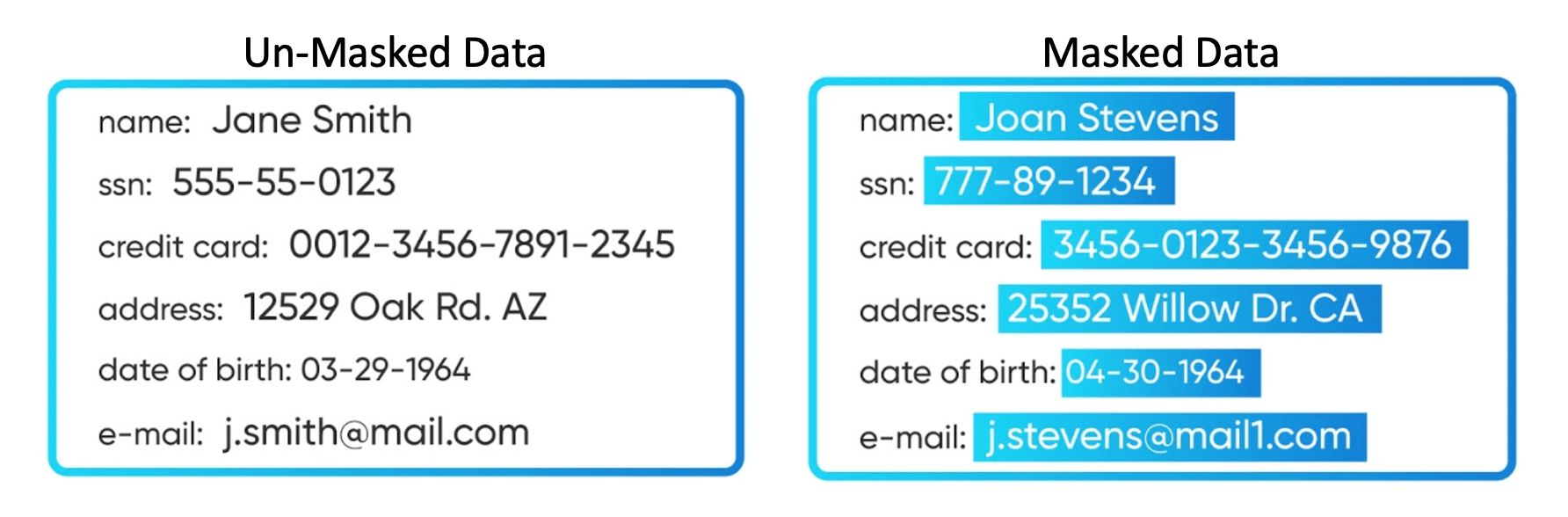
Data masking, an umbrella term for data anonymization, pseudonymization, redaction, scrubbing, or de-identification, is a method of protecting sensitive data by replacing the original value with a fictitious but realistic equivalent. Data masking is also referred to as data obfuscation.
Why is Data Masking Important?
As IT leaders realize that data is key to building data-driven applications and software as well as unlocking competitive advantage, it's becoming increasingly important to provide secure access to data that flows across an organization to innovate faster and at scale, without compromising privacy and security.
The vast majority of sensitive data in an enterprise exists in non-production environments used for development and testing functions. Non-production environments represent the largest surface area of risk in an enterprise, where there can be up to 12 copies for non-production purposes for every copy of production data that exists. To test adequately, realistic data is essential, but real data is notorious for creating runs considerable data security risks.
Data masking eliminates the risk of personal data exposure in compliance with data privacy regulations. By following PII data masking best practices, companies have the ability to move data fast to those who need it, when they need it.
Key Masking Insights: Revealed and Analyzed by the Delphix Experts
How are you protecting sensitive data in non-production environments? In our recent State of Data Compliance and Security Report, 66% cited use of static data masking. Discover other masking insights, including how to use masking for data compliance — without making trade-offs for quality or speed!
Watch the on-demand webinar to find out!
Requirements Your Data Masking Solution Should Fulfill
1. Referential Integrity
Application development teams require fresh, full copies of the production database for their software testing. True data masking techniques transform confidential information and preserve the integrity of the data.
For example, George must always be masked to Elliot or a given social security number (SSN) must always be masked to the same SSN. This helps preserve primary and foreign keys in a database needed to evaluate, manipulate and integrate the datasets, along with the relationships within a given data environment as well as across multiple, heterogeneous datasets (e.g., preserving referential integrity when you mask data in an Oracle Database and a SQL Server database).
2. Realistic Data
Your data masking technology solution must give you the ability to generate realistic, but fictitious, business-specific test data, so testing is feasible but provides zero value to thieves and hackers. The resulting masked data values should be usable for non-production use cases. You can't simply mask names into a random string of characters.
3. Irreversibility
The algorithms must be designed such that once data has been masked, you can't back out the original values or reverse engineer the masked data.
4. Extensibility & flexibility
The number of data sources continues to grow at an accelerated rate. In order to enable a broad ecosystem and secure data across data sources, your data masking solution needs to work with the wide variety of data sources that businesses depend on and should be customizable.
5. Repeatable
Masking is not a one-time process. , it Organizations should perform data masking should happen repeatedly as data changes over time. It needs to be fast and automatic while allowing integration with your workflows, such as SDLC or DevOps processes.
6. Automated
Many data masking solutions often add operational overhead and prolongs test cycles for a company. But with an automated approach, teams can easily identify sensitive information such as names, email addresses, and payment information to provide an enterprise-wide view of risk and to pinpoint targets for masking.
7. Policy-Based
With a policy-based approach, your data can be tokenized and reversed or irreversibly masked in accordance with internal standards and privacy regulations such as GDPR, CCPA, and HIPAA. Taken together, these capabilities allow businesses to define, manage, and apply security policies from a single point of control across large, complex data estates in real-time.
Risk-Based Testing
The goal of any test data management system is shift left testing to reduce defects in production systems and keep the business at optimal performance levels. Having the right test data management strategy is core to a successful DevOps strategy. Companies must be able to decide the best data masking option for them and then use the optimal toolset to extract the maximum business value out of them. They should be able to tweak their release delivery pipelines based on the changes /new features introduced and execute faster cycles. The idea is to limit the effort to the risk being introduced.
What Are the Benefits of Data Masking?
The whole point of security is to have data confidentiality where the users can be assured of the privacy of the data. Data masking done right can protect the content of data while preserving business value. There are different metrics to measure the masking degree, most common being the K-Anonymity factor, but all considerations of using them should ensure shift left testing in order for data security and compliance to be achieved.
Unlike data encryption measures that can be bypassed through schemes to obtain user credentials, masking irreversibly protects data in downstream environments. Data masking not only ensures that transformed data is still usable in non-production environments, but also entails an irreversible process that prevents original data from being restored through decryption keys or other means.
Consistent data masking while maintaining referential integrity across heterogeneous data sources ensures the security of sensitive data before it is made available for development and testing, or sent to an offsite data center or the public cloud—all without the need for programming expertise.
Watch the video below to learn about the benefits of data masking for developers.
Get Started with Delphix Data Masking
Delphix delivers data masking capabilities that enable businesses to mitigate risk and eliminate barriers to fast innovation.
Delphix enables businesses to successfully protect sensitive data through these key steps:
Discovering Sensitive Data
Identify sensitive information such as names, email addresses, and payment information to provide an enterprise-wide view of risk and to pinpoint targets for masking.
Data Masking
Applies static data masking to transform sensitive data values into fictitious yet realistic equivalents, while still preserving the business value and referential integrity of the data for use cases such as development and testing. Unlike approaches that leverage encryption, static data masking not only ensures that transformed data is still usable in non-production environments, but also entails an irreversible process that prevents original data from being restored through decryption keys or other means.
Scaling and Integration
Extend the solution to meet enterprise security requirements and integrate into critical workflows (e.g. for SDLC use cases or compliance processes).
Taken together, these capabilities allow businesses to define, manage, and apply security policies from a single point of control across large, complex data estates.
If you want to learn more about data masking best practices, learn how Delphix provides an API-first data platform enabling teams to find and mask sensitive data for compliance with privacy regulations.