Enterprises must speed up modernization and innovation to keep up and compete in rapidly evolving markets. At the same time, an exponential increase in enterprise data is exacerbating all the data challenges and fueling the need to remove sensitive data or scramble data.
Data privacy and data protection regulations demand that all organizations protect the personal information of customers and employees in production and non-production environments. This makes data scrambling (data masking) a priority.
Stringent data privacy and security mandates—such as the Gramm-Leach Bliley Act (GLBA), General Data Protection Regulation (GDPR), California Consumer Privacy Act (CCPA) and California Privacy Rights Act (CPRA), Health Insurance Portability and Accountability Act (HIPAA), and Payment Card Industry Data Security Standards (PCI DSS)— impose heavy fines and penalties when a business is found to be out of compliance.
Why Data Scrambling?
A string of high-profile data privacy regulation breaches have further increased government scrutiny and focus on data security and privacy compliance regulations. Suppose a data breach occurs and personal information is exposed. In that case, the organization must report the exposure to the appropriate government or regulatory entities and to those whose personal data has been compromised within a certain time frame in compliance with the regulation.
A breach affecting 146 million people cost Equifax $90 million in fines. High-profile breaches at SAP-run enterprises include T-Mobile, one of the fastest 5G networks, which had 54 million customer records—including names, birthdates, Social Security numbers, and other personally identifiable information (PII)— compromised. This resulted in $350 million in penalties and legal liability.
The Purpose of Data Scrambling
Data scrambling (data masking) protects sensitive data by irreversibly replacing database original value with a fictitious value structurally similar to original database values.
The scrambled data can therefore be used for various purposes that require realistic data, such as development, testing software, and training machine learning models.
Static (or persistent) data scrambling (data masking) is the de facto standard for protecting copies of sensitive data in non-production development and test environments. Static scrambled data is protected at rest by changing sensitive data elements such as names, Social Security numbers, and account numbers.
The Difference Between Data Scrambling and Encryption
Encryption uses mathematical calculations and algorithms to encrypt data. Encryption algorithms can be extremely strong but are designed to be reversible so that authorized users can view the original decrypted data. This means that encrypted data can be breached given sufficient compute resources—or a compromised key.
Encrypted data is also not particularly useful for development, testing, training, or analytics because it doesn’t retain the original data format (for example, a 16-digit credit card number may be encrypted as an alphanumeric string consisting of hundreds of characters).
Encrypted data must first be decrypted to support these use cases, thereby exposing the original data. For this reason, encryption doesn't meet regulatory requirements for anonymization, confidentiality or de-identification of PII.
Explore More: Get the complete guide to data masking methods and techniques >>
What is Data Scrambling for Testing?
Protecting test data— typically copies of production data— in non-production environments is often overlooked.
Test data is used in non-production environments for software development, testing, and cloud migration projects, as well as in artificial intelligence (AI) and machine learning (ML), analytics solutions, and reporting tools.
It’s often copied over and over and even downloaded to unprotected devices such as laptops. Today, these non-production environments constitute the largest amount of an organization’s data footprint and make up as much as 90% of the potential enterprise attack surface.

Many companies make each application team responsible for safeguarding the data used in their respective downstream (or lower) non-production environments, including development, testing, quality assurance (QA), staging, and user acceptance testing (UAT).
This approach leaves developers responsible for identifying risk and protecting sensitive data, making it almost impossible to achieve a consistent and robust security posture.
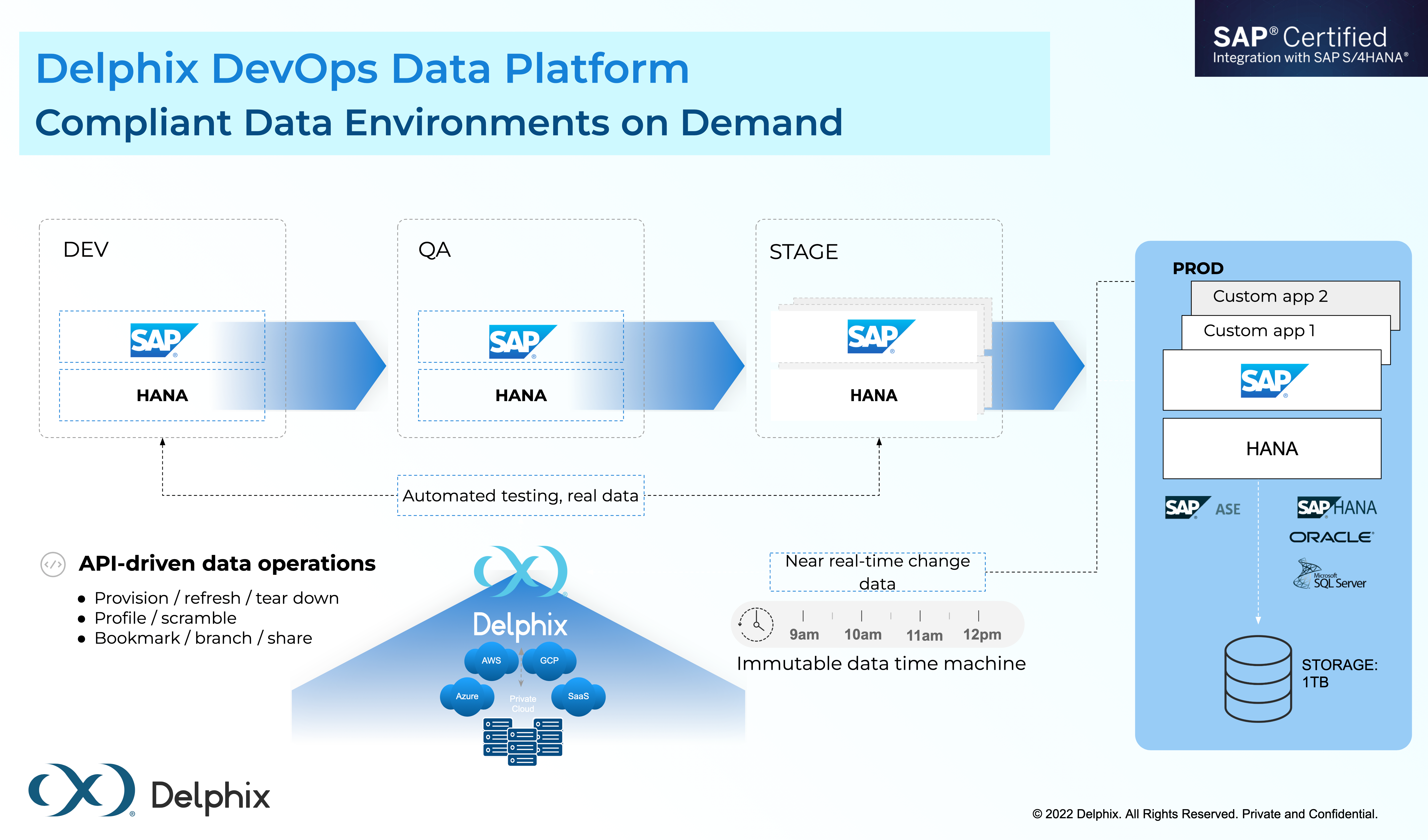
Why Delphix Data Scrambling for SAP?
Inadequate tooling for compliance with global and regional data privacy regulations and laws limits access to high-quality data for multiple use cases. For example, SAP's solution for dealing with sensitive data in S4/HANA leaves them untouched in downstream systems.
It also does not address sensitive data within non-SAP data sources, which must interact with SAP. So referential integrity across systems is lost.
Without continuous access to compliant data-ready environments, essential tasks, including data conversion, development, testing and Q/A and user training for business-critical projects —such as S/4HANA adoption— are risky, costly, disruptive, resource-hungry, and time-consuming.
What is Data Scrambling in SAP S/4HANA?
Delphix's SAP-certified compliance solution enables enterprises to meet ever-changing data privacy compliance requirements and de-risk strategic projects — such as S4/HANA adoption.
Our SAP data scrambling solution consistently discovers, profiles and scrambles all sensitive data across non-production SAP and connected 3rd party applications. This enables SAP-run enterprises to accelerate SAP modernization and innovation to drive digital transformation. Other solutions redact sensitive information at the UI, leaving it untouched in downstream systems and connected non-SAP applications, so referential integrity of the data is lost.
Delphix Data Scrambling at the Data Layer
Data models purpose-built for SAP automate sensitive data discovery, and our algorithms replace these with fictitious yet realistic values. We consistently profile SAP and non-SAP to remove sensitive information in downstream systems, retaining the referential integrity of that data.
Delphix scrambles data once and then delivers safe data to dev, staging, QA, or test environments without the overhead.
The Delphix data scrambling (data masking) solution provides comprehensive SAP-certified data scrambling (data masking) with a business template, pre-identified sensitive fields, and associated algorithms for ECC and S/4HANA. Our Compliance Accelerator enables fast configuration within a few clicks, and the Delphix DevOps Data Platform uniquely combines continuous compliance and continuous delivery to accelerate modernization and innovation.
Learn more about Test Data Management