Key Highlights
- Perform all Continuous Data workflows from a single control plane in Data Control Tower. Full parity across all connectors enables end-to-end data operations including provisioning, syncing, and automation through a unified UI, API, and CLI.
- Drive Hyperscale Compliance end-to-end workflows in Data Control Tower. A new user interface enables end-to-end management of masking jobs, orchestration flows, and real-time execution tracking without switching tools.
- Enable agentic data operations using the Delphix MCP Server. An expanded library of operations allows teams to provision, refresh, and manage data through MCP-compatible AI clients with built-in governance and RBAC controls.
- Continuous Data is now certified for Microsoft SQL Server 2025 across all compatible Windows versions. Ensures seamless compatibility for standalone and clustered deployments without disrupting existing operations.
Recent Delphix Releases
Recent Delphix Releases
Continuous Compliance
- Brazilian CNPJ Compliant: CNPJ and CPF support has been migrated from the legacy BR Financial ID framework to the modern Check Digit framework, delivering improved reliability and long-term support for Brazil's two primary national identifiers. This update ensures full compliance with Brazil's June 2026 CNPJ standard change, which introduces a new alphanumeric format, with no custom configuration required. Brazilian customers will receive this update automatically as part of the May 2026 release.
- ECS Fargate Ready: Containerized masking deployments on Amazon ECS Fargate can now be configured with a read-only root filesystem, a common security requirement in enterprise environments. Required runtime paths are supported via tmpfs mounts, ensuring full compatibility with strict filesystem access policies without compromising masking functionality. No changes to existing deployments are required.
- Mainframe File Format Usability Improvements: Mainframe file formats now support the same streamlined management experience previously introduced for other file types, including named format creation, duplication, and direct export from the compliance engine. These additions reduce manual effort and bring consistency to file format workflows across all supported format types.
- Continuous Compliance in Data Control Tower: Continuous Compliance on Data Control Tower introduces centralized, control plane-driven masking for net new applications. Define compliance logic once, execute it on headless, stateless infrastructure, and track results centrally with full execution history. This release supports built-in connectors including Oracle, SQL Server, and PostgreSQL, with file support and migration support for existing applications planned for a future release. Existing Continuous Compliance users can now directly perform all day-to-day masking engine operations in Data Control Tower Core with no additional license fee.
- Containerized Masking Support for OpenShift: Delphix masking engines can now run on Red Hat OpenShift, giving customers a fully supported deployment option on enterprise Kubernetes platforms without compromising production-readiness.
- Containerized Masking on AWS with ECR and Persistent Configuration: Containerized masking now supports Amazon Elastic Container Registry (ECR) for AWS-native image management. Masking configurations persist across container restarts, reducing operational overhead and ensuring consistent behavior.
AES-256 GCM Encryption: Continuous Compliance now secures all sensitive data on new engines with AES‑256 GCM by default, delivering stronger protection out of the box. Upgrades automatically re‑encrypt stored secrets with AES‑256, giving customers a more secure credential management experience with no configuration required.
- Salesforce Batch Error Collection: The Salesforce masking experience is now improved through increased visibility and traceability of failed masking jobs. Batch-level errors using the Bulk API will automatically log up to 10 sample record IDs where errors occurred.
- Mod11 Check Digit Enhancement: The Continuous Compliance Check Digit framework now includes mod11 support to enable accurate validation and masking for identifiers such as the Australian Tax File Number (TFN). It also adds flexibility for other global formats that rely on similar algorithms to strengthen compliance and broaden coverage for sensitive data across diverse environments.
- Non-Conformant Data Handling: You can now choose to automatically set non-conformant data values to null - either globally or at the individual masking job level through the user interface. This option applies to our latest masking jobs and is not available for older, legacy job types.
- Perforce Brand Refresh: Continuous Compliance got a makeover! Upon installation or upgrade, all accounts will see a variety of fresh, new user interface updates to align with the new Perforce branding, including fonts, colors, buttons, and logos. Please note that all workflows, APIs, and CLIs remain the same.
- File Format Download: Managing file formats just got easier. With this release, you can now download file formats directly from the Compliance Engine. This means you can recreate files when the original is not available, duplicate formats for reuse across multiple sources, and even make edits without needing a re-upload. Initial support includes Delimited, Fixed-Width, JSON, XML, and Parquet.
- Simplified LDAP Setup: LDAP settings entered on the Setup page will now also be applied to the Masking Engine, so you no longer need to configure LDAP in two places.
Faster, More Reliable Job Execution: We’ve completed a major backend modernization of our Continuous Compliance engines, migrating from Kettle to Apache Hop. This upgrade significantly improves job orchestration, engine stability, and scalability for future enhancements. Customers upgrading from older versions are already seeing 3–5x improvements in masking job throughput, depending on data source and configuration.
- Binary JSON Masking: PostgreSQL databases with Binary JSON columns can now be masked, making it easier to secure semi-structured data stored directly in native JSON formats.
- Salesforce Rehearsal Tool: The Select Connector for Salesforce now supports the Delphix Rehearsal Tool (DXRT), enabling teams to simulate metadata package changes - like triggers, workflows, and validation rules - before running any masking job. This pre-flight check helps validate configurations in complex Salesforce orgs, reduce onboarding friction, and prevent runtime errors, all without modifying your data.
- Parquet file ASDD and Masking: Parquet files can now be profiled and masked enabling secure test data management (TDM) and analytics workflows. With Parquet’s high-performance, columnar storage format, enterprises can mask sensitive data efficiently for use in cloud data lakes, AI/ML pipelines, and data analytics platforms.
- AWS ECS Fargate Installations: Continuous Compliance can now be deployed as containers on AWS ECS Fargate. This installation option is in addition to other container platforms including MicroK8s and AWS EKS.
- Engine Sync Memory Improvements: Enhanced memory efficiency for a more robust sync process, especially with large object sets.
- PostgreSQL: Added support for PostgreSQL v15.
- IBM Db2: Added support for IBM Db2 v13 on the IBM z/OS operating system
- Binary Data Support: On-the-fly jobs moving data from databases to files now support binary data columns.
- ASDD of Fixed Width File: Automated Sensitive Data Discovery (ASDD) now supports discovery on delimited and fixed width files with multiple record formats.
- Clear Assignment UX: We added a handy new action icon to instantly remove all applied masking assignments and disable automatic updates for specific fields or columns within an inventory.
- Environment Sorting UX: The Environment column now automatically sorts in ascending order with any other column sort action.
- Application Settings UX: The Application Settings page now includes Expand all and Collapse all buttons for easier management of setting groups.
- SSO Login screen UX: The login customization banner has been expanded to be displayed when Single Sign-On (SSO) is enabled.
- File Masking in Azure Blob Storage: Increasingly, organizations store sensitive application data in object storage buckets. To ensure these buckets can be masked alongside other application data, connecting directly to Azure and masking supported file types is now available.
- Brazilian Financial ID Algorithm: Users can now mask Brazilian CPF and CPNJ numbers out of the box with a new algorithm framework, eliminating the need for custom extensions.
- Improved Auto-Identity Column Job Reporting: Jobs that require the creation of identity columns now report status information on when they are performing that work, resulting in more detailed job monitoring.
- Azure Vault Support: Continuous Compliance now supports Azure Vaults for file masking.
- Oracle Masking: Oracle drop/create index operations on partitioned tables have been enhanced and the driver updated to Oracle’s version 1.3.9.
- Custom UI Branding: Users now have the option of adding their own logo and descriptive text.
- SAP Accelerator: We have updated our templates to include the Split Address Algorithm. Now, these values are masked with referential integrity, regardless of whether they are within a single value or split across multiple. The version structure has also been updated to better identify any dependencies.
- Job and Ruleset Names: For added convenience, we have increased the character limit for masking job and rule set names.
- Google Cloud SQL IAM Authorization for MySQL: Continuous Compliance introduces built-in support for IAM Authorization for MySQL.
- Cockroach DB Connector: For enhanced usability, we have added Cockroach DB to the user interface picklist within the Database Connector wizard.
- Improved automated sensitive data discovery (ASDD) accuracy for files: ASDD now aggregates the discovery results across files of the same format within a discovery job before making sensitive element assignments.
- Automated Sensitive Data Discovery of VSAM file formats: Support has been added for VSAM file formats in the current profiler, bringing parity between the legacy and current profiler. As a result, we have announced the deprecation of the legacy file profiler.
- Google Cloud SQL IAM Authorization for Microsoft SQL Server and PostgreSQL: Continuous Compliance introduces built-in support for IAM Authorization for both Microsoft SQL Server and PostgreSQL instances eliminating the need for an additional proxy. IAM Authorization for MySQL instances will be available in a future release.
- Valid Address Masking: We have introduced a new algorithm framework to allow for valid address masking. Before this, you needed to rely on a services-provided extended algorithm.
- S3 Compatible Storage Enablement: We have introduced file masking support for S3-compatible storage to augment our existing file masking support for AWS S3. You can now connect to GCP using this approach or other S3-compatible targets.
- Remaining UI Component Updates: We have updated and enhanced the final group of UI components, including the Login and algorithm settings pages. We have introduced a new feature to allow customers to add a welcome message.
- Legacy UI removal: As part of the completion of our UI refresh, we have removed legacy UI components that are no longer needed, resulting in improved security and UI performance.
- Modernized User Experience: The user experience has been dramatically improved across all remaining admin sub-pages, including Users, Logs, About, and Email Notifications. A new sub-page for Application Settings has been introduced, enabling users to conveniently adjust application behavior via the UI. The Environments landing page has been upgraded, and the async task is now accessible as a separate page under Monitor. Moreover, the entire UX has transitioned into a single-page application, dramatically enhancing UI performance and user experience. This transition results in smoother interactions and faster load times, among other improvements.
- SAP Accelerator: Introduced a new method to manage secure password properties.
- YugabyteDB: YugabyteDB is now a supported Continuous Compliance data source.
- Discovery of Fixed-Width Files: Automated Sensitive Data Discovery (ASDD) was introduced last year, introducing a complete set of sensitive data identification techniques to databases, JSON, delimited, and XML files. Fixed-width files are now also supported.
- ASDD Improvements: Users can reduce false positives by fine-tuning the ASDD profile sets with a single assignment threshold.
- GCP Secrets Manager Support for Postgres: We have added support for using GCP Secrets Manager with Continuous Compliance connectors to Postgres databases.
- Automated Sensitive Data Discovery for XML Files: Automated Sensitive Data Discovery was introduced last year, bringing a complete set of sensitive data identification techniques to structured data and semi-structured files. Previously, ASDD worked with databases, JSON, and delimited files. It now supports XML files as well.
- New ASDD Default: New Profiling jobs for connectors that support ASDD will now default to the standard ASDD classifier set.
- AWS S3 Connector UI: The new AWS S3 connector is now available in the user interface and API. This connector lets you connect to S3 buckets and mask supported file types.
- User Experience: The Environments Jobs and Connectors pages have been updated, dramatically improving UI performance. Further, there are now ease-of-use wizards for both connectors and jobs and new grid views.
- Automated Sensitive Data Discovery for JSON and Delimited Files: Automated Sensitive Data Discovery was introduced last year, bringing a much more complete set of sensitive data identification to structured data. This has now been expanded to operate against JSON and delimited files.
- File Masking in S3 Buckets: Increasingly, organizations store sensitive application data in object storage buckets. To ensure these buckets can be masked alongside other application data, connecting directly to S3 buckets and masking supported file types is now available.
- User Experience: The Environments Add and Edit Ruleset pages have been updated.
- Character Replacement Algorithm Framework: This framework allows for creating rules to replace specific characters in a string with other characters. For example, you can use this framework to remove inconsistent punctuation in data to maintain referential integrity across data sources.
- New String Chaining Framework: A new framework, StringAlgorithmChain, has been added to simplify the process of creating chained algorithms. This works specifically with String-type algorithms and allows for the creation of output based on the combination of those algorithms. For example, some inputs may have a very low occurrence of specific values (think a department in a company with few members or an uncommon political affiliation). With deterministic masking, the occurrence frequency in the masked data could be used to infer the original value. A custom algorithm or regex framework could remove or alter the occurrence frequency of these inputs and ensure that the data is masked adequately.
- Expanded Classifiers: Automated Sensitive Data Discovery has been expanded to add data discovery for medical codes (CPT, ICD-9, ICD-10), IBAN numbers, swift codes, and bank account routing numbers. Further, we’ve updated the “payment amount” classifier and added a type classifier for license plates.
- Expanded Algorithms: New masking algorithms have been added for swift codes and bank account routing numbers.
- UI Improvements: We have continued improving the user interface, replacing the monitoring function in this release.
- SAP Accelerator: Certified SAP HANA SPS 07, removed the engine command to simplify configuration, and improved error messaging to ease troubleshooting.
- Password Vault Support for MariaDB/MySQL: Supported password vault platforms may now be used to authenticate the connections to MariaDB and MySQL databases.
- Extended Email Algorithm: A new email algorithm has been introduced that allows for chaining existing algorithms to produce a combination of name and domain. For example, this will allow the chaining of existing first name, last name, and domain algorithms. This differs from the “Email Unique” algorithm in that the “Email Unique” algorithm aims to generate a unique email address with a string of characters rather than a standard human-readable name. The details of “Email Unique” can be found in the documentation.
- Masking User Experience Improvements: The masking user experience overhaul continues with an update to the environment's ruleset page.
- New Classifiers: In Automated Sensitive Data Discovery, classifiers identify different data types. We've added new classifiers for gender, sexual orientation, house number, marital status, language, ethnicity, blood type, prescription drugs, companies, job titles, and departments.
- New Secure Lookup Algorithms: To pair with the new classifiers, we've added new Secure Lookup Algorithms for marital status, language, ethnicity, blood type, prescription drugs, job titles, and department.
- SAP HANA: The JDBC Driver version 2.18.13 for SAP HANA SP07 is now supported.
- New Multi-Column Conditional Algorithm Framework: We have added a new algorithm framework that enables conditional masking of a column. For example, this can be used to apply different Secure Lookups to a name column based on a language code. This will eliminate the need for scripting or custom frameworks that were previously required.
- Additional Classifiers and Algorithms: We added additional classifiers, domains, and algorithms to allow you to find and mask age and location data easily.
- Updated User Experience: We continue overhauling the user interface to provide better utility, scalability, and stability. We’ve updated the inventory page for XML and mainframe file formats in this release.
- FTPS Support for Mainframe Masking: FTPS authorization is now available for masking files on mainframes.
- Improved support for Db2 iSeries: The Db2 iSeries database connector now supports automated management of indexes, constraints, and triggers impacted by masked columns. This eliminates custom pre- and post-scripting.
- Improved support for Db2 z/OS: The Db2 z/OS database connector now supports automated management of constraints and triggers impacted by masked columns. This eliminates custom pre- and post-scripting. Note that due to the subtleties of the Db2 z/OS implementation, there is no support for automated management of indexes.
- Password Vault for SAP ASE: Supported password vaults may now be used with SAP ASE (Sybase) databases.
- Improved support for SQL Server: The SQL Server connector now supports leveraging Azure AD Service Principals.
- Redeploy Support (Repave): Continuous Compliance engines may now be disconnected from their storage and redeployed, maintaining the previous configuration and data. Note that redeployment support only works with the same Delphix Engine version.
- Document type masking support for Delimited File Fields (JSON and XML): Increasingly, XML and JSON data are stored in delimited file fields, often due to exporting a database table to a delimited file. Now, these fields can be assigned an appropriate file format, so fine-grained masking of the XML or JSON can be performed.
- Improved Ruleset Auditing: We have enhanced our audit logging to include all items in a ruleset upon its deletion.
- Masking UI Revamp: The database and JSON inventory pages have been completely revamped, with a number of ease-of-use enhancements like filtering, sorting, column-resizing, and overall performance improvements. We highly recommend upgrading to take advantage of this improvement.
- SAP Accelerator: Various enhancements to streamline the rollout of our scrambling templates.
- Updated Classifiers: We’ve added a new tranche of classifiers to discover additional sensitive data. These new classifiers include elements like medical record number, full name, age, and IP address. We have also improved several existing classifiers to better discover sensitive information, including credit card and bank account numbers.
- Password Vault for IBM Db2 on LUW, iSeries, and z/OS: Supported password vaults may now be used with Db2 databases on LUW, iSeries, and z/OS systems.
- Updated User Experience: We continue overhauling the user interface to provide better utility, scalability, and stability. In this release, we’ve updated the inventory page for fixed-length and delimited file types and the file format settings page.
- FTP Support for Mainframe MVS Storage: The Compliance Engine now offers enhanced functionality with FTP support, enabling direct access to the mainframe MVS storage environment.
- Data Discovery and Authentication Support: Automated Sensitive Data Discovery now supports OAuth for Salesforce or Kerberos for Oracle Database, Microsoft SQL Server, and SAP ASE.
- ESXi 8.0 U1: Continuous Compliance may now be run on VMware ESXi 8.0 U1.
Continuous Data
- Continuous Data in Data Control Tower: Data Control Tower now delivers full feature parity with Continuous Data across all supported data connectors. Oracle, Microsoft SQL Server, PostgreSQL, SAP ASE, Unstructured Files, and all other connector types are now fully supported in Data Control Tower, including environment creation, dSource linking, snapshot ingestion, and VDB provisioning, through both the UI, API, and CLI.
- This milestone completes the multi-release Continuous Data parity initiative. Data Control Tower is now the recommended platform for all day-to-day database administration, giving administrators a single control plane across their entire Continuous Data footprint with full self-service access for database administrator users.
- We encourage all Delphix administrators to install Data Control Tower and migrate their database management workflows. As part of this release, Continuous Data documentation has been migrated into and updated for the Data Control Tower documentation site. Engine-based usage of Continuous Data should continue to use the previously existing Continuous Data documentation.
- SQL Server 2025 certification: Continuous Data is now certified for Microsoft SQL Server 2025 across all compatible Windows versions, with full support for both Standalone and Cluster configurations.
- SQL Server Target Availability Groups for CDC and TDE: Change Data Capture (CDC) and Transparent Data Encryption (TDE) are now supported in SQL Server Availability Group (AG) target environments, strengthening security while enabling advanced database capabilities.
- SQL Server VDB Provisioning of READ_ONLY Sources: Delphix can now provision SQL Server VDBs from READ_ONLY source databases. Snapshot and point-in-time provisioning are supported across standard environments, Failover Cluster Instances (FCI), and Availability Groups (AG).
- SAP ASE 16.1 on RHEL 9 Certified: Continuous Data is now certified for SAP ASE 16.1 running on RHEL 9.4 and RHEL 9.5 including Kerberos-enabled deployments. All existing ASE workflows including dSource sync (Backuplog and Dump History), encrypted database sync, and VDB provisioning, refresh, and rewind are supported.
- Azure V6 Series for Delphix Engines: Continuous Data now supports Microsoft Azure V6 series virtual machines, enabling customers to take advantage of newer, higher-performance instance types. Support is delivered through Azure Compute Gallery, which provides centralized image management with versioning and the configuration required by V6 families (such as Hyper-V Generation V2 and NVMe disk controllers) making it easier to deploy engines consistently across regions and at scale.
- Continuous Data in Data Control Tower: All available Oracle and SQL Server UI and API features in the Continuous Data engine are now fully enabled in Data Control Tower. Existing Continuous Data users can now directly perform all day-to-day Oracle and SQL Server operations in Data Control Tower Core with no additional license fee.
- Elastic Data Cache Priority: Designated virtual databases running on Elastic Data now deliver consistent, block-storage-like read performance. By proactively reserving and warming block storage cache, this capability minimizes latency variability and ensures predictable performance from the moment a virtual database is provisioned. This is especially valuable for critical workloads that require stable, high-speed data access.
- Upgrade to Java 17: The java toolkit running on the host has been upgraded from JDK 8 to JDK 17, delivering improved performance, security enhancements, and long-term support aligned with modern Java standards. Bring Your Own JDK (BYOJ) has also been updated to support JDK 17 only. Older JDK versions including JDK 8 are no longer compatible.
- Continuous Data for Kubernetes: This release introduces a Kubernetes-native Operator for PostgreSQL, enabling automated provisioning, refreshing, snapshotting, and lifecycle management of containerized Virtual Databases (VDBs) through declarative YAML workflows. Users can provision and manage PostgreSQL VDBs in Kubernetes without manual scripting or deep Kubernetes expertise, accelerating test data delivery in CI/CD pipelines. A license entitlement to Data Control Tower Self Service or Data Control Tower Enterprise is required to enable this capability.
- TLS Support for ASE with Kerberos Authentication: SAP Sybase ASE environments configured with both Kerberos authentication and TLS encryption are now supported. Kerberos verifies the identities of both the Delphix Engine and the Sybase ASE instance before a session is established, while TLS ensures all transmitted data remains encrypted and protected from interception.
- Granular User Access Level Permissions: User Management has been enhanced with a drop-down menu offering three distinct access levels, replacing the previous simple checkbox. Engine administrators can now assign permissions more precisely by role and responsibility.
- Oracle 26ai: Oracle 26ai is now supported starting with Continuous Data 2026.2.0.0. Refer to the Oracle matrix for supported configurations.
- Oracle AIX 7.3 Certification: Certification has been added for AIX 7.3 for Oracle databases, starting with Continuous Data Engine 2025.3.0.1 and later. Specific technology levels (TL2 SP4, TL3 SP1, TL4 or later) must be installed.
- MySQL Connector: This release introduces support for HashiCorp Vault integration, enabling secure, runtime retrieval of MySQL credentials without storing them in Delphix configurations. Customers can now align with enterprise secrets management policies and reduce operational risk through automated credential rotation. Additionally, the connector adds support for selective database ingestion from AWS Aurora MySQL environments using GTID-based replication, streamlining data provisioning workflows for PaaS deployments.
- Oracle EBS Connector: This release introduces support for custom environment variables in adcfgclone workflows, enabling greater flexibility and improved troubleshooting. It also adds early detection of missing inputs in the adclonectx workflow to reduce provisioning failures, and expands support for low-privilege user workflows and ksh shell compatibility on AIX environments.
- SAP HANA Connector: This release adds support for SAP HANA environments with SSLEnforce enabled, ensuring secure SSL/TLS connections are automatically established for compliant, encrypted access.
- Connector Documentation Migration: Continuous Data connector documentation has moved from the Continuous Data documentation site to the Ecosystem Hub, consolidating all connector content into a single, consistent location . Note the terms "datasets," "data sources," and "plugins" are now consistently referred to as "connectors" across the documentation. No product functionality has changed.
- Oracle Incremental Virtual to Physical (V2P) For RAC: Traditional Virtual to Physical (V2P) exports data from a virtual database (VDB) to a physical database and can be valuable during disaster recovery or ransomware scenarios. Upon an event, immediate use of a VDB provides rapid operational support while the physical database is hydrated in the background, allowing for full production restoration. This new capability restores any deltas on the VDB back to the physical database to ensure no transactions are lost is now available for Oracle RAC.
- Multiple Oracle Key Vault clients per host: A robust, GA-quality CLI/API-only feature to support multiple Oracle Key Vault clients per host for customers who require security separation between databases running on the same host.
- MSSQL Clusters Certification: Continuous Data is now certified for Windows Server 2025 running MSSQL clusters, including Failover Cluster Instances (FCI) and Always On Availability Groups (AG).
- Shielded VM for Delphix GCP Images: We’ve strengthened our Shielded VM on GCP support by adding vTPM and Integrity Monitoring to enhance platform trust. The vTPM securely stores cryptographic material and records the measured boot state, enabling validation that the system boots only with trusted firmware and software components. Integrity Monitoring continuously verifies the runtime system state to detect unauthorized changes.
- Configurable dSource Hooks: A system-level configuration option allows sysadmin users to enable or disable dSource hooks that run on the production hosts. This enhancement provides organizations with greater flexibility to manage dSource hooks according to their own operational and security policies, rather than enforcing a one-size-fits-all approach. By default the configuration option is disabled when installing new engines and is enabled when upgrading any engine to this release.
- AES-256 GCM Encryption: Continuous Data now secures all sensitive data on new engines with AES‑256 GCM by default, delivering stronger protection out of the box. Upgrades automatically re‑encrypt stored secrets with AES‑256, giving customers a more secure credential management experience with no configuration required.
- PostgreSQL Connector Enhancements: Several small enhancements to the PostgreSQL Data Connector, including Azure Entra authentication for smoother and more secure integration with Azure Flexible PostgreSQL sources, faster ingestion through parallel index restoration, simplified privilege elevation for easier deployment, and support for custom Target Clone Database Names to give teams more flexibility during ingestion.
- MariaDB Connector: Our database platform library has been expanded to include a new MariaDB connector. This is a standard connector included with your Continuous Data entitlements.
- Cassandra Multi-Node Staging: The connector can now create dSources that span database instances across multiple hosts, providing more flexible and scalable multi‑node staging deployments.
- SAP HANA SPS08 Certified: This update adds support for SAP HANA 2.0 SPS08 on SUSE15 SP5, enabling customers to run workflows on the latest certified platform combination.
- MongoDB Connector Enhancements: This release introduces support for masking and redacting LDAP parameters to improve security and compliance. It also enables modifying VDB configuration parameters through enable/disable operations. Additionally, certification has been added for Mongosync v1.16.0 and v1.18.0 on RHEL 9 with MongoDB 8.x, broadening compatibility across environments.
- ServiceNow Spoke: The Enable Catalog Access item now automatically assigns the required lower
- Incremental Virtual to Physical (V2P): Traditional Virtual to Physical (V2P) exports data from a virtual database (VDB) to a physical database and can be valuable during disaster recovery or ransomware scenarios. Upon an event, immediate use of a VDB provides rapid operational support while the physical database is hydrated in the background allowing for full production restoration. This new capability restores any deltas on the VDB back to the physical database to ensure no transactions are lost. Incremental V2P is now available for Oracle and SQL Server through the API layer. Note that support for Oracle Real Application Clusters (RAC) is not part of this release and will be added in a forthcoming release.
- SQL Server AG Fast Provision and Fast Refresh: Continuous Data currently supports API-driven provisioning and refreshing Virtual Databases (VDBs) on SQL Availability Groups (AG) using a traditional backup-and-restore approach, where operation time depends on the size of the database. With this release, we introduce Fast Provision and Fast Refresh to eliminate the backup-and-restore step, resulting in significant performance improvements with consistent and predictable completion times.
- Google Cloud Platform (GCP) Secure Boot: Secure Boot is currently supported by Google Cloud’s Shielded VM security features by adding an extra layer of protection against threats that can survive reboots. Only software signed with trusted cryptographic keys stored in the UEFI key database can be launched.
- Multiple Oracle Key Vault (OKV) Clients (Preview): Existing support for OKV clients has been extended from one client to multiple clients per host through the CLI/API. This enhancement enables security separation for Oracle databases on the same host and improves compliance for TDE key management.
- SAP HANA SSFS Encryption: SAP Secure Store in the File System (SSFS) encryption support for the SAP HANA Data Connector is now available to ensure data volume, log, and backup encryption.
- CockroachDB Point-in-Time Restore and Snapshot: You can now ingest and snapshot a specific point in time from your source CockroachDB database. These snapshots can then be used to provision or refresh downstream virtual databases (VDBs).
- MySQL 8.4 Certification: MySQL 8.4 database versions are now fully supported when using the 2025.1.0+ data source connector.
- MongoDB on Ubuntu 24 LTS: Ubuntu 24 LTS operating system are now fully supported for MongoDB when using the 2025.2.1+ data source connector.
- Delphix Self-Service End of Life: We have removed Delphix Self-Service (aka JetStream) from Continuous Data and upgrades are disabled when any Self-Service configuration exists. The next generation of Self-Service experiences are now available in Data Control Tower.
- Offline Replication: Delphix now enables secure data replication between environments that cannot be directly connected, using an offline replication option. Initially supported via NFS only, the feature allows data from a source engine to be safely transferred and then accessed by a target engine in another segregated zone. This approach ensures compliance with strict isolation requirements while still providing seamless data movement across environments.
- Incremental V2P for Oracle (Preview): Traditional Virtual to Physical (V2P) exports data from a virtual database (VDB) to a physical database and can be valuable during disaster recovery or ransomware scenarios. Upon an event, immediate use of a VDB provides immediate operational support while the physical database is restored in the background allowing for full production restoration. This new capability restores any deltas on the VDB back to the physical database to ensure no transactions are lost. Contact your Delphix Account Team to participate in our Preview program ahead of its full general availability in November 2025.
- AWS Secure Boot Instance: Secure Boot support is now available for Delphix engines. This enhances the existing Amazon EC2 secure boot process by adding an extra layer of protection against threats that can survive reboots. It ensures instances only launch software signed with trusted cryptographic keys stored in the UEFI key database.
- IBM DB2 Transparent Data Encryption: The IBM DB2 connector now introduces support for Transparent Data Encryption (TDE) with Backup Only (DPF and non-DPF) and HADR ingestions, enabling ingestion of encrypted source backups and provisioning of encrypted VDBs.
- MongoDB Multi-Node Certification: The MongoDB connector now supports creating the staging database across multiple nodes for Staging Push ingestion. In addition, we have certified MongoDB v7.x and v8.x versions.
- PostgreSQL Certification: PostgreSQL connector supports PostgreSQL v16.x on RHEL v8.5.
- Oracle Cloud Infrastructure Vault with TDE: We now support Oracle Transparent Data Encryption (TDE) with Oracle Cloud Infrastructure (OCI) Vault. This enables secure key management for Oracle databases protected with TDE and managed within OCI-native services, aligning with enterprise cloud security requirements.
- Oracle Isolated Keystores with TDE: We added support for Oracle's Isolated Keystores, which allow each PDB (Pluggable Database) to have its own TDE keystore. This enhances security and compliance by enabling finer-grained encryption key management within Oracle Multitenant environments.
- Virtual to Physical for Oracle on File Systems: We now support exporting virtual Oracle databases to physical, non-multitenant Oracle instances running on File System storage using RMAN (backup as copy) as the file transfer mechanism. This capability expands the use case support of Delphix by enabling users to repave, migrate, or restore virtual data into production-like physical infrastructure.
- Oracle RMAN RATE for SnapSync: A new RMAN RATE parameter has been introduced when taking a snapshot of an Oracle dSource via the CLI. If this parameter is set, an upper limit will be set for the megabytes per second read rate while taking a snapshot of an Oracle dSource ensuring RMAN does not consume excessive disk bandwidth and degrade online performance.
- CockroachDB Advanced Data Operations: Admins and self-service users can now create snapshots for CockroachDB VDB. This feature also allows the creation and sharing of self-service bookmarks and the provisioning of new VDBs from the saved point in time (PIT).
- Yugabyte Anywhere: Starting with YugabyteDB plugin v2025.1.0, users can provision a staging database directly through Yugabyte Anywhere (YBA). Staging database can be restored from backups stored in Azure Blob Storage using the YBA restore workflow, streamlining cloud-native recovery process. Full support for YB-Controller–generated backups on Azure Blob Storage is available when creating or resyncing staging databases.
- Oracle EBS Certifications: Delphix Continuous Data Engine 2025.2 is now certified for the following Oracle E-Business Suite configuration:
- Oracle E-Business Suite: 12.2.14
- AD/TXK Code Level: 16 or higher
- Oracle Database: Version 19.26.0.0 or later
- Operating System: RHEL 8.10
For more information, refer to the Oracle EBS support matrix page.
- SAP HANA Certification: Certification has been achieved for SAP HANA 2.0 SPS 07 on RHEL v9.4.
- Repave for Disaster Recovery: This feature automates engine backups every 15 minutes, storing them in a secure Delphix storage location. In a DR scenario, users can quickly repave a new engine by selecting the last good backup, eliminating manual backup and preparation steps for faster engine recovery.
- IBM s390x Platform support: With the Premium Connector for Mainframe, the IBM s390x platform can be virtualized with Continuous Data. The solution is currently supporting Linux distributions Ubuntu 22.04 and RHEL 9.4 and greater.
- Legacy Self-Service Unavailable: As another step towards End of Support, new installations of Continuous Data will by default no longer include the legacy Self Service UI, APIs, and CLIs. Engine upgrades to versions released between now and the September 2025 End of Support date will be unaffected. Please contact your Delphix Account team if your organization does not have a plan to migrate to Data Control Tower for Self Service.
- Always Encrypted in SQL Server: Continuous Data Engines now provide support for Always Encrypted, which is a feature designed to protect sensitive data by encrypting it both at rest and in transit. Customers need to generate encryption keys, store them in the Windows Certificate Store or a Key Vault, and transfer or import certificates to required hosts.
- MySQL: We introduced property inheritance into the connector to simplify provisioning and configuration by passing my.cnf properties from the dSource to downstream VDBs.
- Oracle E-Business Suite (EBS): Full hook utility support for the AIX operating system was added. In addition, all AppsTier installations on a single environment will be correctly discovered to enable users to quickly consolidate Source and Target environments.
- IBM Db2: Added to existing connector releases the support of IBM Db2 v11.5 and v12.1 on the RHEL v9.5 operating system.
- Oracle 23ai: Oracle 23ai is now supported starting with Continuous Data 2025.2.0.0. Refer to the Oracle matrix for supported configurations.
- SQL Server Scaling: SQL Server can now conditionally accommodate dSource sizes larger than the current 63TB limit. If the mount volume exceeds the default 90% utilization threshold and the feature flag is enabled, Delphix will automatically expand the volume to 255TB.
- SQL Server on Linux: Introduced a new select connector for Continuous Data to support SQL Server on Linux 2017 and 2019 virtualization. This offering complements the existing Continuous Compliance masking capabilities.
- Managed Admin Inheritance: To improve flexibility and security, admins can now control whether newly created admins can themselves create more admins. Existing admins can also have this ability removed if needed. Previously, any admin could create new admin accounts, which automatically inherited the same privileges.
- IBM Db2: Added support for IBM Db2 v11.5 on the IBM AIX v7.3 operating system. Standardized the dataset’s storage group and container data paths to improve resiliency during ingestion and provisioning operations.
- PostgreSQL: Added support for PostgreSQL v17 for the RHEL v9.x operating system.
- SQL Server Availability Group - You can now provision virtual databases within a SQL Server Availability Group configuration on your target environment. This support enables the automation of SQL Server VDB provisioning directly into Availability Groups, streamlining deployment processes. Additionally, customers will enjoy substantial storage savings, as all nodes within the Availability Group are stored in Delphix Continuous Data's efficient storage. This feature is compatible with both Elastic Data and traditional storage configurations, providing flexibility for a range of use cases.
- Data Connector Documentation and Downloads Migration – We have moved connector documentation from the Delphix Continuous Data to the Delphix Ecosystem documentation site. This shift will enable us to version our connector documentation independently of engine releases. To match, connector downloads will move within the Delphix Downloads Portal's Ecosystem section.
- Virtual-to-Physical (V2P) of Oracle Multi-tenant, Pluggable Databases: Currently, users can export Oracle database data via V2P for Oracle multitenant pluggable databases to ASM. With this feature, we are enabling the data export to physical filesystems as well.
- Oracle Virtual Pluggable Database (vPDB) Provisioning: Continuous Data Engines now support provisioning an Oracle vPDB from a snapshot of a non-multitenant source database to an existing virtual container database (vCDB). Previously, only physical container databases were supported as targets. It is important to note that the target virtual container database must already exist, and creating a new virtual target database during the conversion process is not supported. Transparent Data Encryption (TDE) is also not supported.
- Yugabyte: The Yugabyte Anywhere (YBA) offering can now integrate with Yugabyte VDBs to enhance operational efficiency, such as in using YBA's alerts, monitoring, or backups.
- Documentation: Broad improvements are introduced in the datasets documentation for Oracle and SQL Server data sources.
- Repave for Elastic Data Engines: Following the initial phase of delivering Repave for all-block engines, we are delivering the same capability for engines configured with Elastic Data. This allows customers to replace Delphix Continuous Data engines with a new engine (same version) and reattach its storage.
- AWS Amazon Linux Support for Unstructured Data (vFiles): Adds support of AWS Amazon Linux to our Unstructured Data Virtualization (vFiles) solution.
- ESXi 8.0 u3 Support for the Delphix Platform: Starting from the 27.0 release, customers can upgrade or deploy engines with ESXi 8.0 u3.
- IBM Db2: Added version validation between a snapshot and Target environments to ensure provision and refresh compatibility.
- CockroachDB: Introduced the ability to download backups from Google Cloud Storage and ingest from a multi-node staging server. These features will allow for faster ingestion and better dataset snapshots.
- IBM Db2: Certified IBM AIX v7.2 on POWER9 hardware.
- MySQL: Certified MySQL and Percona v8.0 on RHEL v8.9 and lower. Redacted potentially sensitive data during the generation of support bundles.
- NFS and iSCSI Encryption: The data transfer between Continuous Data and target/staging environments takes place through NFS & iSCSI. In our continuous effort to maintain the highest security standards, with this release we are introducing the ability to encrypt the iSCSI traffic.
- Auto Restart of Oracle VDBs and VPDBs: The previous version of Continuous Data (24.0.0.0) supports the automatic restart for single-instance (i.e. non-RAC) environments only. We enhanced this capability to allow auto-restart of VDBS, VPDBS, and PDBS in Oracle RAC environments when the nodes are restarted.
- Windows Connector Cipher Enhancements: We are enhancing the user experience and security of configuring the Windows connectors ciphers.
- MySQL on AWS Support: Certified MySQL on Amazon Linux 2 host environments and the Staging Push linking strategy for AWS RDS and RDS Aurora.
- Oracle E-Business Suite (EBS): Added support for specifying a second Oracle EBS Application Tier to support linking from disaster recovery sites. In addition, the Application Tier password updates now occur following the Enable/Disable operations to hasten the rotation process.
- Engine Object Limit: To improve scalability, we are expanding the number of objects a Delphix Continuous Data engine can handle from 400 to 750.
- K8s Driver: Introduced the ability to provision a PostgreSQL dataset using the K8s Driver from an existing PostgreSQL dSource. In addition, we have added Volume Cloning support, Tagging of VDBs, and various bug fixes. Please consult the K8s Driver documentation for more information.
- PostgreSQL: Added the ability to provision datasets from existing PostgreSQL dSources. Simply ingest a source using the latest PostgreSQL connector and follow the K8s Driver Provision and enable documentation for more information.
- Password Vault Credential Cache: In the current Password Vault implementation, the Delphix engine retrieves credentials on each Environment access request, which can quickly scale due to normal dataset activity. We are enhancing the feature to allow customers to have the ability to 'cache' the given credentials and prevent excessive calls to the configured Vault.
- Elastic Data for GCP: We have expanded support of Elastic Data for Google Cloud Platform (GCP) object storage. Initially, our support is limited to GCP Standard Object Storage.
- Sybase TLS/SSL: Delphix Continuous Data now supports security protocols for ASE instances that only use TLS/SSL connections authenticating via a client certificate.
- PostgreSQL: We have added RHEL 9.x certification.
- Documentation: We continue to make broad improvements across multiple areas of our Connector documentation, including Cassandra, MySQL, and SAP HANA. We have also revised documentation to clarify new upgrade paths for all connectors.
- Windows AD Logging: Our SQL Server install base is growing fast, and our largest customers are experiencing excessive Active Directory login entries for their domain controllers. We have made improvements to provide the right amount of information without overflowing the logs.
- Fluentd API Activity Log: We now ship Nginx access logs to the Fluentd service to provide an audit trail of off-engine API activity. This visibility improves the ability to detect vulnerability exploit attempts.
- YugabyteDB: The YugabyteDB database is now a supported Continuous Data source.
- MySQL: Certified AWS RDS and RDS Aurora using the Staging Push ingestion mechanism and streamlined the Staging Push configuration for all sources.
- Cassandra: Added further redaction of values to the support bundle and resolved a malformed IPv6 address issue.
- Oracle EBS: Please refer to the Oracle EBS’ fixed issues for more details about this release.
- PostgreSQL: Resolved an issue where some expected tables were missing after a single database refresh or restore, which broke a previously working ingestion.
- Documentation Updates: We have continued to make broad improvements across multiple areas of our documentation, including Oracle EBS.
- Oracle: RedHat Enterprise Linux (RHEL) 9.0 and 9.3 are now supported with Oracle 19c.
- IBM Db2: The IBM DB2 connector now supports IBM AIX 7.2 and RHEL 9.2.
- MySQL: The user interface has been improved during the linking of a MySQL dSource in the wizard. Users will notice that only properties applicable to the chosen linking method are shown.
- Documentation Updates: We have continued to make broad improvements across multiple areas of our documentation, including CockroachDB and MySQL.
- Customizable Local Listeners for Oracle MT RAC VDBs: Database administrators must configure database listener parameters for multiple reasons, notably security, performance optimization, and resource management. We now support customizing local listeners when provisioning a VDB in an Oracle RAC environment. In addition, this allows you to provision a VPDB into a new VCDB in a non-RAC or RAC environment, update local listeners for a VDB in a RAC environment, and update local listeners for a VCDB in a non-RAC or RAC environment.
- Support Delphix Operations for Oracle RAC VDBs/VPDBs During Downtime: Oracle RAC is used for production databases to ensure their availability 24/7. To comply with business continuity guidelines, we now support the following VDB/VPDB operations when one or more hosts of the Oracle RAC clusters are down: Provisioning, enable/disable, refresh, start/stop, and rollback. This enhancement includes VDBs/VPDBs in VCDBs and Linked CDBs.
- Staging Push Online DB Mode for SQL Server: We now support database online mode for Staging Push dSources for SQL Server, keeping the source database open for transactions, as needed. Before this enhancement, Staging Push source databases were required to be only in restoring mode. This enhancement is supported for SQL Server deployed on-premises and in the cloud (for self-managed databases and SQL PaaS environments).
- IBM Db2: RHEL v9.2 is now supported for IBM Db2 v11.5, including IBM Db2 v11.5.9.
- MySQL: Added Staging Push support for AWS RDS and AWS RDS Aurora MySQL. Certified Amazon Linux 2 as staging and target host environments.
- Oracle E-Business Suite (EBS): Oracle EBS’s DB Tech Stack on IBM AIX v7.2 is now supported. The EBS App Tier is not supported on IBM AIX v7.2.
- SAP HANA: HANA SPS 06 and SPS 07 are now supported on the SUSE Operating Systems.
- Expanded RedHat Support: RHEL 9.0 and 9.3 are now supported for Oracle 19c. RHEL 9.3 is supported with vFiles.
- Documentation Updates: We have continued to make broad improvements across multiple areas of our documentation, including Couchbase, IBM Db2, MongoDB, and MySQL.
- Documentation Updates: We have made broad improvements across multiple areas of our documentation, including the Delphix Glossary, Datasets’ Getting Started, and PostgreSQL.
- UI for Object Storage Connectivity Modification: We have implemented several enhancements to simplify the modification of object storage configuration. Specifically, the following can be modified: key rotation for security (key-based authentication), endpoint URL, region, and the ability to change between key-based and profile-based authentication.
- Improved Elastic Data Migration: Leveraging Elastic Data with Continuous Data provides significant cost savings by leveraging object storage and block storage. We have decreased the time to execute migrating an engine from a standard Continuous Data Engine to an Elastic Data Engine without the need for replication.
- TDE support for Hardware Security Module (HSM) solutions: Managing Oracle TDE (Transparent Data Encryption) across multiple Oracle environments can be challenging. TDE management solutions have been introduced to solve this challenge and are growing in popularity. Delphix can now connect to and leverage tools like OKV and CypherTrust to perform all operations within TDE environments managed by any of these tools.
- SAP HANA: HANA SPS 06 and SPS 07 are now supported on the SUSE Operating Systems.
- MongoDB: MongoDB is now supported on the RHEL 9.0 Operating System.
- Decreased VDB Downtime: There are two types of upgrades for Continuous Data: full upgrades, where VDB downtime is incurred during a system reboot, and deferred updates, where there is no system reboot and, therefore, no downtime. Note that some features will require a full upgrade. We have improved the upgrade process for the full upgrades to delay the VDB downtime to just the system restart. VDBs remain running during the upgrade and are only down for the system reboot portion.
- Object Storage Modification: Key rotation, endpoint URL, regions, and authentication types may now be modified for existing connected object storage through the API and CLI.
- NFS Encryption: We have extended support for Repave and Oracle RAC configurations with NFS encryption.
- IBM Db2 HealthChecker: The HealthChecker can now validate staging and target environment configuration to simplify implementation. This joins existing support for Oracle E-Business Suite (EBS).
- PostgreSQL: Provided WAL Logs will no longer automatically roll forward a dSource.This action will only occur when a dSource snapshot is taken to eliminate unknown changes.
- SAP HANA: Certified SAP HANA SPS 06 and 07.
- NFS Encryption: Using encryption over NFS between Continuous Data engines and the target and staging hosts is now supported. Please consult with your account team as to whether this is an appropriate fit for your needs.
- MySQL on Linux: Manual Ingestion has been renamed to Staging Push to standardize on Dephix’s established ingestion architectures. Strengthened the refresh and snapshot workflow to minimize occasional failures. Please review the upgrade path for installation guidance.
- Oracle E-Business Suite (EBS): Updated our virtual database provisioning hooks to support the Solaris operating system. We recommend this release to all users as it contains various bugs and security fixes.
- Couchbase: We have added support to define multiple buckets, configure RAM sizes, and the ability to ingest multiple full backups. Additionally, the connector will now report data source sizing.
- Microsoft SQL Server Backup: We have enhanced the useability of data ingestion from Microsoft SQL Server on Azure by dynamically modifying the Access Control Lists (ACLs) for files and folders that different staging and target environment users own.
- Redeploy Support (Repave): Continuous Data engines may now be disconnected from their storage and redeployed, maintaining the previous configuration and data. Redeployment support only works with the same Delphix Engine version. Currently, engine redeployment is not supported with Elastic Data engines.
- Delphix Elastic Data Engine Migration: Continuous Data Engines using all-block storage may now be migrated to Elastic Data engines using object storage. Previously, this was only accomplishable via replication.
- Export an Oracle non-multitenant or PDB snapshot to a physical Oracle ASM or Exadata database: This feature enables you to export data from an Oracle non-multitenant PDB snapshot or timeflow point to a physical Oracle database that uses Oracle Automatic Storage Management (ASM). This feature is especially useful for Oracle target environments running on Exadata or ExaCC systems.
- Oracle VDB Provision to a Different Patch Version: You may now provision a VDB with a different Oracle patch version than the source. This will allow you to test Oracle patches on VDBs before committing to production.
- SQL Server Provisioning Performance: We are enhancing the vDB provisioning performance for SQL Server by eliminating the need to run the checkpoint operation.
- Improved Access Control List (ACL) Update time for SQL Server Filestream Files: During SQL Server transaction log ingestion, the time to update ACL on filestream files is longer than the transaction log interval, causing delays. We are opting to skip checking ACLs during VDB operations to overcome this issue.
- Downloadable Fluentd Logs: The fluentd integration allows Continuous Data events to be exported to various supported third-party systems. You can now download Fluentd logs for analysis to better debug using those systems.
- Changed Support Policy for Cloud Instance Types: Previously, we provided guidance on specific cloud instance types. Given the proliferation of instances and the speed at which the cloud vendors update these, we have moved to a system of general guidance–describing which families of instances are recommended and minimum requirements. These can be found in the documentation.
- IBM Db2 Connector: SSL/TLS connections are now supported with HADR dSources. In addition, we have revised our linking process to guide configuration based on the ingestion method more clearly.
- MySQL/Linux Connector: The creation, rollback, and refresh actions of VDBs are blocked when the target environment’s installed MySQL version is not the same as the dSource’s installed MySQL version. The Managed Source Data report and TB usage calculations now report on MySQL data.
- Couchbase Connector: Couchbase v7.1.x Community and Enterprise Editions are now supported.
- Elastic Data: We’ve rebranded “Cloud Engines” to “Elastic Data.” Continuous Data with Elastic Data allows you to leverage lower-cost object storage and traditional block storage. This dramatically decreases the operational cost of Continuous Data while enabling new use cases like long-term archival and retention.
- Private Data Center Elastic Data: Previously, Elastic Data was only available for Continuous Data Engines deployed in AWS (using S3) or Azure (using BLOB storage). We now support deploying Elastic Data with on-premises, S3-compatible object storage arrays.
- Elastic Data on Oracle Cloud Infrastructure: Elastic Data may now be used in OCI, providing decreased operational costs and new use cases, as mentioned above.
- Replication Failback: In the case of a failure on a primary Continuous Data Engine, failover may be used to swap operations to a secondary Engine. Previously, this was a one-time, terminal action. With failback, you may restore operations to the primary engine if the failure has been resolved or if you simply want to test the failover process.
- Oracle Staging Push: The Staging Push method of ingestion now supports point-in-time provisioning of data.
- IBM Db2: SSL/TLS connections are now supported with HADR dSources.
- MySQL/Linux: There is now guidance for upgrading Source, Staging, and Target environments from MySQL 5.7 to v8.0. In addition, new guardrails have been introduced to prevent incompatible refresh and rollback operations.
- PostgreSQL: All RHEL v8.x operating systems are now supported. In addition, new protections have been introduced to prevent accidental modification of parameters via VDB Config Template configuration.
- SAP HANA: VDB provisioning has been improved in scenarios when SAP HANA services “scriptserver” and others are missing volume information.
- Support for Adoptium Java: By default, the Continuous Data Engine will push the Adoptium OpenJDK to connected environments. In addition to this, you can provide your own Oracle Java should you wish. Now, you also can provide your own Adoptium JDK.
- ESXi 8.0 U1: Continuous Data may now be run on VMware ESXi 8.0 U1.
Data Control Tower
- Continuous Data in Data Control Tower: Data Control Tower now delivers full feature parity with Continuous Data across all supported data connectors. Oracle, Microsoft SQL Server, PostgreSQL, SAP ASE, Unstructured Files, and all other connector types are now fully supported in Data Control Tower, including environment creation, dSource linking, snapshot ingestion, and VDB provisioning, through both the UI, API, and CLI.
- This milestone completes the multi-release Continuous Data parity initiative. Data Control Tower is now the recommended platform for all day-to-day database administration, giving administrators a single control plane across their entire Continuous Data footprint with full self-service access for database administrator users.
- We encourage all Delphix administrators to install Data Control Tower and migrate their database management workflows. As part of this release, Continuous Data documentation has been migrated into and updated for the Data Control Tower documentation site. Engine-based usage of Continuous Data should continue to use the previously existing Continuous Data documentation.
- This milestone completes the multi-release Continuous Data parity initiative. Data Control Tower is now the recommended platform for all day-to-day database administration, giving administrators a single control plane across their entire Continuous Data footprint with full self-service access for database administrator users.
- Continuous Data for PaaS (Early Access): Data Control Tower-managed PaaS Instances and PaaS DBs now include a Compliance tab on their details pages. The Compliance tab provides an integrated view of Masking and Profiling status, connector management, and job collection assignment — enabling compliance workflows directly within Data Control Tower. The Compliance tab is only available on managed downstream databases and instances. It is not displayed on Root Sources or unmanaged databases to prevent accidental masking of production data.
- Hyperscale Compliance on Data Control Tower for Oracle (Early Access): Data Control Tower now includes an integrated user interface for managing Hyperscale Compliance workflows for Oracle databases. Users can configure and execute Hyperscale masking jobs, monitor orchestrator flows, and track job execution and status, all from within Data Control Tower, without needing to interact with Hyperscale directly.
- This release brings together orchestrator flow management, job creation and monitoring, and real-time execution tracking into a unified Data Control Tower experience, with algorithm synchronization across Hyperscale nodes handled automatically in the background.
- To participate in the Early Access program, please contact [email protected].
- Delphix MCP Server Additional Operations (Community): The Delphix MCP Server has been extended with full CRUD operations for Continuous Data and platform administration. Users can now perform a wide range of data workflows, including provisioning VDBs, refreshing datasets, creating and managing bookmarks, taking snapshots, updating tags, and executing bulk operations, directly through any MCP-compatible AI client.
- This opens new opportunities for AI-driven workflows, such as understanding storage relationships and data lineage, or combining VDB provisioning with infrastructure automation (e.g., Terraform deployments), significantly simplifying Delphix onboarding and day-to-day operations for both administrators and self-service users.
- Operations are organized into persona-based toolsets to limit token consumption and improve AI quality. A manual confirmation mechanism is included for destructive actions that could result in permanent data loss. The ability to perform these operations is governed by each user's existing Data Control Tower access controls and RBAC permissions.
- For additional information, see the MCP Server GitHub repository.
- AI Help Update: The AI Documentation Help now automatically searches the documentation that matches the currently installed Data Control Tower version, ensuring that responses are accurate for your specific release. Searches are scoped to Data Control Tower and Ecosystem documentation (Data Connectors and DevOps Integrations) only — for additional documentation or to search across versions, visit the public documentation site.
- Dark Mode (Preview): Data Control Tower now supports a dark display mode. Users can toggle between light and dark modes by selecting the moon or sun icon in the top-right corner of the interface. This is a per-user preference that persists across sessions.
- Delphix Synthetic Data (Preview): A pre-GA version of Synthetic Data Generation is available through a separate, standalone Data Control Tower release for early adopters.
To participate in the Preview program, please contact [email protected].
- Continuous Data for PaaS (Early Access): Automate and mask PaaS databases throughout your cloud test data landscape using Data Control Tower, without requiring Delphix virtualization engines on the target infrastructure. Continuous Data for PaaS (previously PaaS Data Automation) is available as an Early Access release.
- Continuous Data in Data Control Tower: All available Oracle and SQL Server UI and API features in the Continuous Data engine are now fully enabled in Data Control Tower. Existing Continuous Data users can now directly perform all day-to-day Oracle and SQL Server operations in Data Control Tower Core with no additional license fee.
- Continuous Compliance in Data Control Tower: Continuous Compliance on Data Control Tower introduces centralized, control plane-driven masking for net new applications. Define compliance logic once, execute it on headless, stateless infrastructure, and track results centrally with full execution history. This release supports built-in connectors, including Oracle, SQL Server, and PostgreSQL, with file support and migration support for existing applications planned for a future release. Existing Continuous Compliance users can now directly perform all day-to-day masking engine operations in Data Control Tower Core with no additional license fee.
- Continuous Data for Kubernetes: This release introduces a Kubernetes-native Operator for PostgreSQL, enabling automated provisioning, refreshing, snapshotting, and lifecycle management of containerized Virtual Databases (VDBs) through declarative YAML workflows. Users can provision and manage PostgreSQL VDBs in Kubernetes without manual scripting or deep Kubernetes expertise, accelerating test data delivery in CI/CD pipelines. A license entitlement to Data Control Tower Self Service or Data Control Tower Enterprise is required to enable this capability.
- Data Library: A new Data Library provides a unified view of all Data Control Tower-managed data assets across the platform, including dSources, virtual databases, PaaS DBs, PaaS Instances, and Connectors. The Data Library serves as a central starting point for all data-related workflows in Data Control Tower, regardless of whether datasets are virtualized, PaaS, or traditional on-premises.
- Documentation AI Help: A new side-panel AI chat lets users ask questions against Data Control Tower and Ecosystem documentation without leaving their current workflow.
- Hyper-V Appliance Support: Installation of Data Control Tower is now supported on Hyper-V.
- Connector Documentation Migration: Continuous Data connector documentation has moved from the Continuous Data documentation site to the Ecosystem Hub, consolidating all connector content into a single, consistent location to align with our Data Control Tower platform model. Note the terms "datasets," "data sources," and "plugins" are now consistently referred to as "connectors" across the documentation. No product functionality has changed.
- Continuous Data Oracle Parity: All available Oracle UI and API features in Continuous Data are now fully enabled in Data Control Tower. We encourage all users to start migrating all day-to-day Oracle operations to Data Control Tower.
- Delphix MCP Server (Preview): Developers can now leverage the power of AI to query information about their Delphix Platform using a MCP Server. This read-only, Preview implementation is open source, community supported, and leverages your enterprise AI Services. For additional information, see the MCP Server GitHub repository.
- AES-256 GCM Encryption Support: Data Control Tower now protects all stored credentials with AES‑256 in GCM mode, with every secret automatically re‑encrypted at upgrade. This strengthens default security and delivers a more robust foundation for managing sensitive credentials.
- License Usage Visibility: Administrators can now centrally monitor entitlement usage across the entire Delphix platform, including Continuous Data, Continuous Compliance, and Elastic Data. This robust report has summaries and historical trends as well as telemetry across a wider set of data platforms.
- Perforce App Switcher: Users of multiple Perforce products can now seamlessly navigate across experiences and discover adjacent Perforce software solutions.
- Engine Management using the Terraform Provider: Continuous Data and Compliance Engines can now be configured and registered on AWS and Azure using the Terraform Provider for Delphix. Admins can also automate the configuration of block and/or object storage, making cloud deployments more flexible and automated.
- ISO 42001 certification: In February 2026, Perforce Delphix Data Control Tower received ISO 42001 certification. ISO 420001 certification is the first international certification that validates an organization’s responsible management of Artificial Intelligence (AI), through an AI Management System (AIMS). This certification ensures that organizations are utilizing AI in an ethical, transparent, and compliant way to cover risk management, governance, and data privacy for their products and, in turn, their customers. You can find our announcement on this, as well as all our compliance and security updates, on our Trust Center.
- Continuous Data Feature Parity for Oracle: Headless engines for Continuous Data have arrived! Data Control Tower can now be used to manage all data operations for your Oracle data, providing a unified alternative to the engine level UI and API. Now is the time to start migrating Oracle virtualization workloads to Data Control Tower. All other data sources will be available in Data Control Tower in early 2026.
- Unlimited Connected Engines: Engine connectivity limits have been removed from all Data Control Tower tiers to enable the Data Control Tower platform vision for all customers, which includes a unified user experience, global access control and centralized reporting. This uncapped engine licensing includes Data Control Tower Core, which is available to all Delphix customers with Continuous Data and/or Compliance entitlements.
- Perforce Intelligence Search: Leverage the power of AI using a natural-language interface to quickly answer questions from within the Data Control Tower user interface. This generative AI-based search taps into our official documentation and knowledge base content. This AI feature is disabled by default and communicates with a hosted Perforce AI service from the browser.
- ServiceNow Spoke Enhancement: Administrators no longer need to manage individual user access in ServiceNow thanks to a new Enable Catalog User operation available in the Delphix Spoke. This further streamlines the ServiceNow workflows that trigger Delphix automation.
- License Usage Visibility (Preview): We are introducing powerful new administrative views designed to give you complete visibility into your Delphix DevOps Data Platform's entitlement usage including data source sizes. This capability is now available behind a feature-flagged Preview and is scheduled for GA release in early 2026. Contact your Delphix Account Team to participate in our Preview program.
- Hook Template Management: Users can easily import existing hook templates from their engines and re-use them directly within their dataset provision and management for all data platforms. This capability is another key milestone as we centralize the entire Delphix experience from the engines into Data Control Tower.
- ServiceNow Spoke: Transform your Self-Service experience with our new out-of-the-box ServiceNow Catalog items including Refresh Operations, Bookmark Management, and Enable Catalog User. The Enable Catalog User feature is particularly valuable for organizations looking to scale their ServiceNow adoption efficiently by automatically onboarding new users.
- PostgreSQL v15 Certified: Data Control Tower deployments using Kubernetes or OpenShift can now be configured to run on an external PostgreSQL v15.x database. This enhancement expands your deployment flexibility including backup and recovery approaches and enables recent PostgreSQL features.
- Perforce Intelligence: We are releasing Perforce Intelligence in Data Control Tower Enterprise, a new foundational AI service that optionally embeds a supported language model into Data Control Tower for offline, secure, and intelligent workflows for your Delphix products in future releases. Moving forward, many new enhancements will leverage this framework enabling the Delphix experience to take full advantage of modern AI to improve productivity, reduce costs, and enhance security.
- AI-Powered Synthetic Algorithms: The first application of Perforce Intelligence is to remove the manual, error-prone process of building secure lookup lists by leveraging language models that automatically generate synthetic lists. This AI approach reduces bias, accelerates deployment, and improves masking quality.
- Delphix Telemetry: We have introduced the ability to centrally register Data Control Tower installations and share anonymous usage information with Delphix. When enabled, you can expect faster support resolutions, proactive account management, and improved product features. This service will ultimately replace the legacy engine-based Phone Home system. To get started or understand what metadata we collect, please see our documentation.
- Perforce Brand Refresh: We got a makeover! Upon installation or upgrade, all accounts will see a variety of user interface updates to align with the new Perforce branding, including fonts, colors, buttons, and logos. Please note that all workflows, APIs, and CLIs remain the same.
- Oracle Cloud Infrastructure (OCI) Installation: We now support installation of the Data Control Tower Virtual Appliance on OCI.
- Terraform Provider: VDB Group Tags can now be added, modified, or removed to manage access control and general organization. This matches tag functionality with the other supported Terraform resources.
- ServiceNow Spoke: The ServiceNow Yokohama release is now supported.
- Data Connections: Provides a single source of truth for all data sets across the Perforce Delphix platform, including dSources, VDBs, and Compliance connectors. By intelligently merging multiple references to the same database, Data Control Tower simplifies reporting, streamlines administration, and enables rapid workflow creation using consistent, reusable connection metadata. As Data Control Tower expands to support more source types - across databases, PaaS, and IaaS - this data library will scale with it.
- Data Engine Storage Report: Admins can now monitor storage health for Continuous Data engines and take quick action when free space is running low. This view is enhanced with new data points including Held Space inclusion, aggregation of CDBs and vCDBs, and total size counts.
- Kubernetes Driver for Oracle: Introduces the ability to provision Oracle Single Tenant VDBs on Kubernetes (K8s), including Azure’s AKS and AWS’s EKS. Infrastructure management is now combined with data provisioning to simplify management and minimize costs. This joins existing support for PostgreSQL and Unstructured Files (vFiles).
- Terraform Provider: Added update-in-place support for Environment resources and PostgreSQL dSources to enable modification of the object’s state. In addition, the beta flag around the Terraform “Import” command has been removed for many resources, and it’s now a fully supported feature.
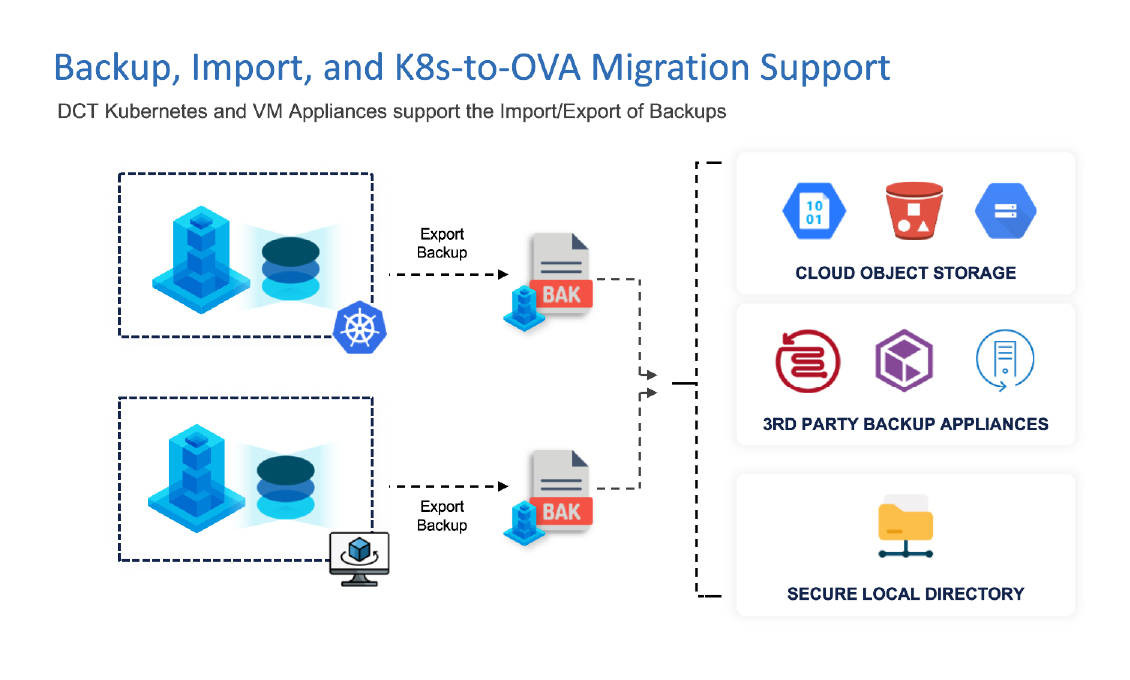
- VM Appliance Backup and Kubernetes Migrations: Data Control Tower CT now supports the ability to perform a complete Backup and Recovery for the OVA installation. In addition, administrators can now migrate from K8s to the OVA installation using this same backup approach.
- Data Engine Storage Report Dependencies: The existing report has been enhanced to enable review and deletion of dSource and VDB dependencies. On deletion, the presented dependency tree has been simplified for easier review to better understand the data object and storage impact. In addition, the graph has been revised for better ordering of values.
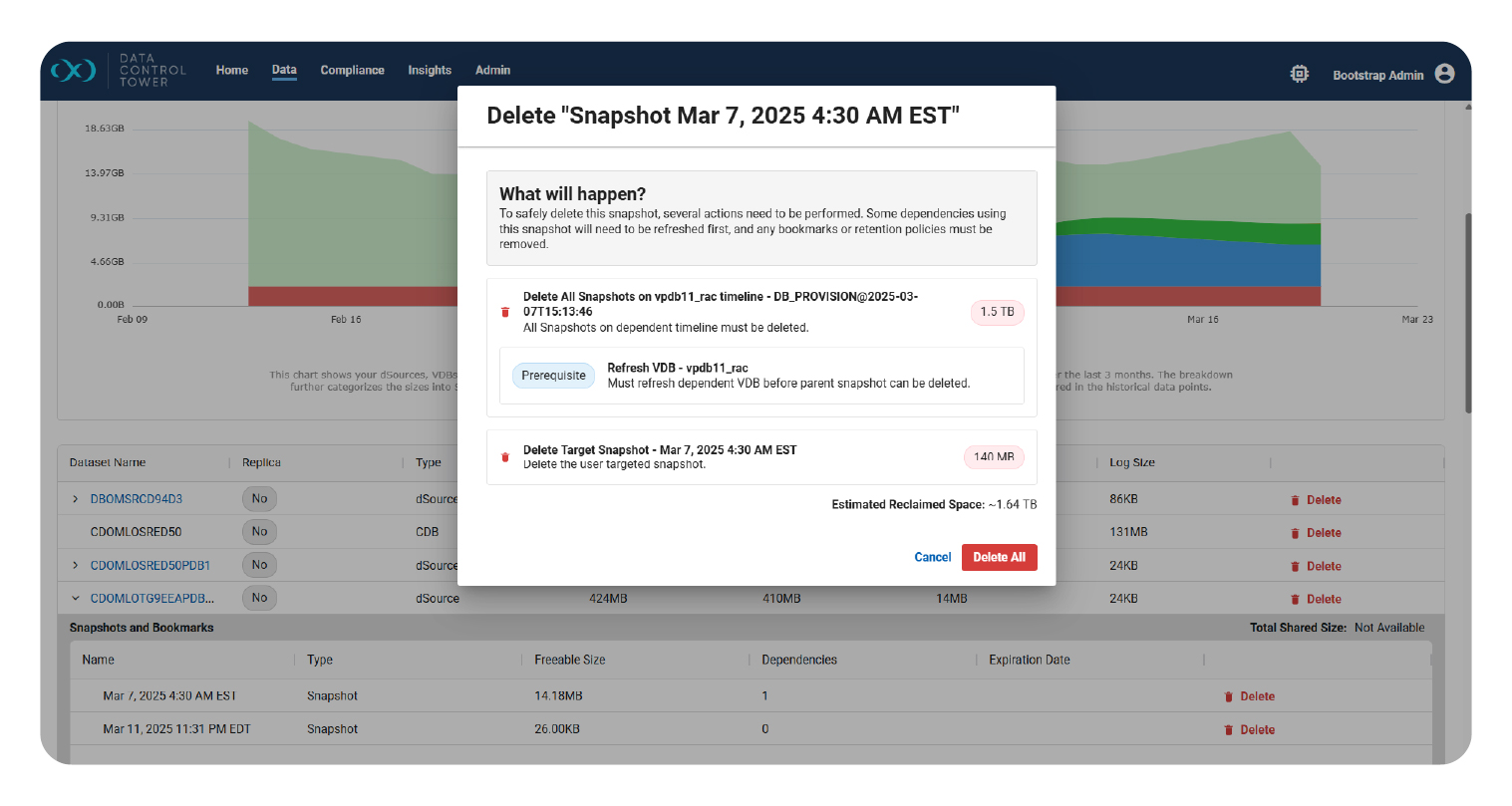
- Oracle and SQL Server User Experience: We have introduced VDB migrate, upgrade, and downgrade support for Oracle and SQL Server into the Data Control Tower UI & API. In addition, VDB/dSource snapshot and dSource Staging Push attach support have been added for SQL Server. These enhancements support our effort to move to a headless engine model, where all engine operations can be performed from Data Control Tower.
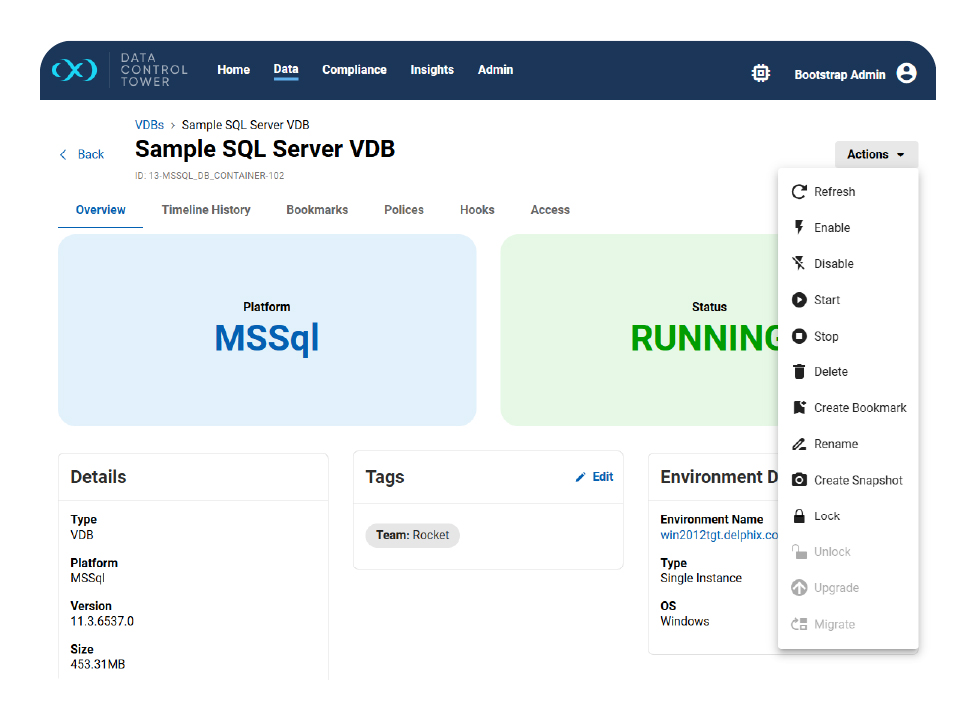
- Kubernetes (K8s) Driver Masked VDB: We added the ability to provision masked virtual databases (VDBs) through the `isMasked` flag. This enables the triggering of preconfigured Selective Data Distribution (SDD) compliance jobs and accurate representation in Data Control TowerDCT’s Data at Risk report.
- Terraform Provider Oracle dSource Drift Detection: We enhanced the provider with drift detection and update-in-place support for the Oracle dSource resource. In addition, the default dSource ingestion logic has changed to wait for the sync and snapshot process by default and introduced the beta Oracle dSource import feature.
Data Control Tower
- Curated Views: Administrators can now tailor the user interface by role, ensuring each user only sees the navigational options they need. This streamlined approach significantly enhances the self-service user experience.
- Job Collections: Data Control Tower now supports Job Collections, which groups and executes Continuous Compliance jobs in a user-set order. This feature greatly improves the ease of running complex sets of jobs on VDB refresh.
- Engine Storage Capacity Management: Data Control Tower now delivers an engine-centric view of storage usage, showing growth trends over time for dSources, VDBs, Held Space, and other metrics. Additionally, administrators can easily reclaim space by identifying and removing unnecessary dSources and VDBs.
- VDB Group Self Refresh: The VDB Group dataset now has the capability to orchestrate a refresh given a timestamp from itself or parent’s timeline.
- ServiceNow Spoke: The Delphix integration with ServiceNow has been certified to run with the ServiceNow Xanadu version.
- Data Control Tower Core – Delphix has introduced 3 license tiers for Data Control Tower – Core, Self Service and Enterprise. All Delphix customers with active Continuous Data and/or Continuous Compliance licenses now gain access to Data Control Tower Core, offering foundational capabilities enabling you to quickly centralize and automate your data operations.
- Central Tag Management – All tags in Data Control Tower can now be visualized on a new Tag Management page on the Admin tab. This experience improves visibility of where and how tags are being used as well as the capability to drill down into a specific tag.
- VDB Group Self Refresh – A VDB Group can now be refreshed to its latest set of snapshots on demand. This operation was formally known as Rewind.
- Terraform Provider Drift Detection - Introduced the ability to modify virtual database (VDB) resources created through the Terraform provider. This enables drift detection of your data sets. In addition, we released the "import" capability as a beta feature to enable VDBs created outside to be managed via Terraform.
- ServiceNow Spoke Expansion – We have added capabilities to support two new catalog items: Refresh from Parent and Relative Snapshots.
- Data Control Tower VM Appliance: As an alternative to the existing Kubernetes-based deployment model, Data Control Tower now offers a VM-based closed appliance model for net new deployments of Data Control Tower. This model closely resembles the traditional engine hosting model offering a simpler management experience for admin teams.
- VDB Groups: Introduced the full standard action drop down set to VDB Groups, including Start, Stop, Enable, Disable, Lock, and Unlock. Various smaller refinements and performance improvements based on user feedback.
- Date/Time Refresh: When selecting an unavailable point in time in the Refresh > Date/Time wizard, the two closest options are now presented.
- Password Updates and API Key Rotation: Users can re-generate API Key and update their Data Control Tower passwords. Administrators can set an expiration policy in the Admin > Authentication tab to improve security practices.
- Session Timeout: By default, after one hour of inactivity, users will be logged out of Data Control Tower. Administrator can set a preferred timeout policy in the Admin > Authentication tab.
- VDB Groups UX Enhancements: Data Control Tower has provided a major update to VDB groups including a new UI to view and manage grouped VDBs and operational enhancements such as bookmark support. All of this provides an improved integration testing experience for Delphix customers.
- Faults, Alerts, and Actions data: Continuous Data Engine Details now displays faults, alerts, and actions data to provide better auditing.
- Bulk Environment Refresh Support: Data Control Tower now can perform environment refresh from both the API and UI for one or more environments at the same time with a single operation. This is particularly powerful when combined with tag-based filtering.
- Enterprise Compliance Visibility: Data Control Tower provides visibility of nearly all Compliance engine objects. This critical central reporting capability provides filterable list views with richly detailed contextual views customized for each object type.
- ServiceNow Spoke Currency: Added support for Vancouver and Washington releases.
- VDB Group Creation Wizard: VDB groups can now be created in the Data Control Tower UI using a creation wizard that guides you through the selection of a filtered list of VDBs. VDB Groups are used to coordinate data automation operations such as Refresh across multi-VDBs simultaneously.
- VDB Group List and Details Views: Data Control Tower now visualizes VDB Groups via a list view found under the “Data” tab. This shows all VDB Groups and associated statuses, platform composition, and the last refresh timestamp. Clicking into a VDB Group’s details will show the combined VDBs as well as critical time and masking details. Please note, additional actions, wizards, and views will be available in future releases.
- Replica reporting details: Data Control Tower can now break down object–specific detail for replication targets to pair with existing details such as the last successfully completed replication. This will provide additional visibility for administrators tracking Disaster Recovery configurations and statuses.
- Failover and Failback Support: Data Control Tower supports failover with failback support on a replica’s detail screen. This enables administrators to identify downed engines and to orchestrate disaster recovery centrally from Data Control Tower’s user interface.
- Discovery Policies (formerly Profile Sets) Read Only: Data Control Tower now visualizes existing Discovery Policies (known as Profile Sets) on connected Continuous Compliance engines. This enables administrators to visualize how the engine employs classifiers (or legacy expressions) during sensitive data discovery from a single page.
- Data Vault Replication Policy Configuration: Data Control Tower now supports the ability to configure replication profiles for Data Vault Target engines from the UI.
- Snapshots and Bookmarks on the Timeline: The VDB timeline now presents snapshots and bookmarks together in chronological order. This updated presentation makes it easier for any user to understand the bookmark's context and the rough time a refresh will take to complete from the Log Delta time.
- Oracle dSource Hook Management: Pre Sync, Pre LogSync, and Post Sync hooks can be created, edited, reordered, and deleted from the dSource's Hooks tab.
- VDB-to-Bookmark Tag Inheritance: The default permission model has been updated so that users who have Edit Tags permission on a VDB will also have Edit Tags permission on the VDB’s bookmarks.
- Data Classifier support: All Classifiers and Expressions, from any connected Continuous Compliance engine, can be viewed on the Data Classifier tab. This enables administrators to better monitor their classifier configurations and easily share details with security teams.
- Custom Hook Support: Data Control Tower has augmented hook support for pre-existing VDBs. Users can now create, update, and delete hooks as well as determine hook execution order.
- Selective Data Distribution (SDD) Replication Support: Data Control Tower now supports a SDD-specific user experience that creates replication profiles specifically for compliant prod-to-non-prod VDB distribution for developer access to masked data.
- Rule Sets Detail Views: Data Control Tower's Rule Set UI now includes detail views on associated jobs, table and column-level detail on masking rule assignments, as well as a sensitive data coverage analysis to provide a visualization of data risk.
- Bookmark Migration for VDB Groups: The Delphix Self-Service migration workflow has been expanded to now support multi-VDB containers. These will be recreated in Data Control Tower as VDB Groups. Read our Delphix Community blog post to learn how to migrate single or multi-VDB containers, templates, and bookmarks.
- Delphix Self Service-to-Data Control Tower Migration Utility: Delphix Administrators can now quickly migrate existing Self Service bookmarks, containers, and permissions to Data Control Tower.
- Compliance Enterprise Visibility: The user interface now includes list views for Data Classes (formerly known as domains), Compliance File Uploads, Rulesets, and Connectors. Many of those objects have detailed complex relationships and metadata to help administrators proactively manage the connected compliance estate.
- Replication Management: Admins can create, update, monitor, and delete replication profiles.
- Auto-tagging of Custom Tags: Users can now define, per connected engine, a series of custom tags to be applied to all objects pulled into Data Control Tower via telemetry, enabling a fast and efficient way to populate tags within Data Control Tower.
Oracle CDB Operations: Centrally start, stop, and delete Oracle CDBs from Data Control Tower and report on those CDBs with enhanced capabilities with the addition of “enabled”, “group name”, and “status” attributes. - Bookmark Data Timestamps: The VDB Timeline and Bookmarks pages now have bookmark data timestamps available to enable users to track the lineage of the source data.
- Data Control Tower Reporting Framework Updates: We have introduced column-based filtering on all list views to provide a spreadsheet-like user experience. Session retention has also been introduced for the VDB list view. This lets you maintain page configurations such as filters, sorting, search, etc., even after navigating off of the page.
- Data at Risk Report: Data Control Tower now displays sensitive data risk for all database connectors across your Continuous Compliance engines. This report enables users to proactively manage data compliance by identifying where unmasked sensitive data may exist across all environments.
- Block Storage Report: Administrators can quickly measure and manage storage across all Continuous Data engines using a new storage trend report. This report also includes a three and six-month projection to assist administrators with capacity forecasting.
- Storage Savings Report: The ROI of virtualization can now be quickly measured using a granular storage savings report.
- Auto Tagging: Data Control Tower can now propagate engine-based groupings as tags in Data Control Tower, including dataset groups, environments, and applications. This feature can be enabled at engine connect and will stay in sync with an engine until turned off.
- Replication Profile Management: Users can now centrally create, update, and delete replication profiles via Data Control Tower APIs. Additionally, Data Control Tower can now create replication profiles from the Data Control Tower UI; this wizard can be found on the Replication Profiles List page. Additional replication UI functionality will be added in subsequent releases.
- Oracle Container Databases: Oracle container infrastructure (CDB and vCDB) can now be centrally administered via the Data Control Tower API and UI, including the ability to enable and disable it.
- Simplified Bookmark Sharing: Bookmarks can be shared with other users by easily toggling the “Bookmark Visibility” value. This simplification now closely aligns with the experience of Self-Service.
- Timeline Display: To accommodate customer feedback, additional details have been introduced on the Timeline History tab to help users find where their data is coming from.
- Terraform Provider: Changed the default value of “wait_time” to 0 and removed the “storage_size” variable to improve upgrades.
- Enhanced Bookmarks Organization/Search: The bookmark user experience has been updated, including search on VDB and dSource details pages. VDB visibility on the central bookmark, the VDB’s bookmark, and VDB wizard pages has been improved. Bookmarks are also supported via Data Control Tower-orchestrated replication.
- Timeline History UX Updates: Data Control Tower has consolidated the active timeflow and timeflow history tabs into a single timeline tab. The new page is similar to the former timeflow history but now with a search bar and sorting capabilities. You can now sort upon timeline activation [default], timeline creation, parent timeline location, and origin timeline location. This enables better identification and filtering of your data sets’ varying timelines.
- Global Compliance Object Sync Report: The compliance Global Object is the aggregate representation of all multiuse objects (algorithm, domains, rule sets, etc) on a compliance engine. These objects, among others, are versioned by the compliance engine to clarify if there have been settings or behavioral changes. Data Control Tower now surfaces those versioning details to better illustrate if and where there are object differences. This could, for example, reveal whether or not two engines will mask with identical outputs.
- Oracle CDB Inventory Report: Data Control Tower now features an Oracle Container Database (CDB) report that lists virtual and physical resources across all connected engines and associated pluggable database (PDB) relationships.
- MongoDB and Delimited File Support via the Data Control Tower UI: Data Control Tower now supports executing and modifying existing MongoDB and Delimited File Hyperscale Compliance jobs.
- Kubernetes Driver: We have added support for taking a VDB volume snapshot and provisioning a VDB from a snapshot. In addition, we resolved various bug fixes that were impacting general dataset creation and deletion.
- Terraform Provider: The Terraform Provider now has a new “Database” resource that allows users to create and delete PostgreSQL environment source configurations.
- Algorithm Centralization: We plan to centralize orchestration and control in Data Control Tower. To enable better visibility into compliance, masking algorithms across all connected Continuous Compliance Engines can now be centrally viewed in Data Control Tower.
- Expanded Source Linking: Over the past few years, we have introduced Staging Push to allow users to bring their data to Continuous Data. The Data Control Tower UI now supports linking for Oracle and SQL Server using Staging Push. Further, we’ve expanded standard linking to SAP ASE, PostgreSQL, Db2, MySQL, HANA, and MongoDB.
- Hyperscale Compliance UI Enhancements: Several improvements have been added, including enabling the management of Continuous Compliance Engine assignments for Hyperscale Jobs.
- Data Control Tower Toolkit Enhancements: Based on customer feedback, several improvements have been made to our fully supported CLI for Data Control Tower. Notably, dct-toolkit allows users to provide engine names as values for 'id' options.
- Continuous Data Jobs Progress: Users can track job progress in real-time through the Operations UI.
- Improved Replication Visibility: Replication is used for data movement, disaster recovery protection, and sensitive data distribution, which requires setting up relationships between Continuous Data Engines. To provide better visibility on these relationships, we have added them to Data Control Tower. To further simplify this user experience, the target Continuous Data Engine and dataset are now linked together.
- Engine Performance Trendlines: Historical trendlines have been added to the recently introduced engine performance reports.
Kubernetes (K8s) Driver: To expand our Kubernetes Driver’s capability, we now support AWS Elastic Kubernetes Service (EKS), introduced Data Control Tower API Usage monitoring, and fixed various issues to ease adoption.
- Delphix Kubernetes Driver: Virtual databases can be provisioned into containers through Helm charts and kubectl commands using a new, pre-built Data Control Tower integration. Teardown of these containers can also be automated, enabling ephemeral infrastructure for Kubernetes-based applications.
- Engine Performance Reports: New Continuous Data and Compliance reports have been added to improve the central management of engine infrastructure performance. You can now view allocated resources and track performance for all connected engines, including disk latency, network latency, and throughput.
- Hyperscale Compliance Jobs: Data Control Tower now has support for creating, managing, and executing Hyperscale Compliance jobs. The concept of Engine Pools has been introduced along with several other enhancements to refine the overall experience.
- User Experience Improvements: Several enhancements including customizing the columns across all tables, increased color contrast for better accessibility, simplified navigation across tabs, and a variety of visual style improvements.
- Replication Tag Inheritance: Data Control Tower now offers API-based simplified tag management for parent/child replication deployments, optionally syncing source tags to a target replica.
- Oracle and SQL Server Source Linking: Linking sources for Oracle and SQL Server is now supported in the User Experience, along with creating bookmarks.
- Terraform Provider: A new Terraform resource facilitates creating and deleting Oracle dSources. This expands on the existing data source support with the provider.
- Hyperscale Compliance User Interface: Data Control Tower now provides an interactive UI that enables creating and editing Hyperscale instances and the ability to update/execute Hyperscale jobs.
- Engine Replication Management: Data Control Tower has added the capability of mapping replication parent/child relationships within its data library, including failover scenarios where replicas become the primary. This enables accurate monitoring and administration of replication workstreams.
- Operations Monitoring Action Bar: Continuously view all running operations relevant to a user group while performing other Data Control Tower UI activities using the new action bar.
- Expanded dSource Linking: Create dSources via Data Control Tower for MS SQL Server Single and Clustered Instances and Oracle and SQL Server Staging Push instances.
- Data Source Provisioning: Provision any supported data sources through the Data Control Tower UI or APIs.
- Terraform Provider: A new Terraform resource to manage creating and deleting PostgreSQL dSources.
- Jenkins Plugin: Support for CloudBees CI has been added.
- Hyperscale Compliance User Experience: Hyperscale Compliance can now be managed in Data Control Tower. Hyperscale orchestrators can be registered with Data Control Tower to provide visibility to engine clusters and mount points. Masking jobs and job execution history can be viewed with pre-built reports. This is available in a controlled release, so please contact your account team to activate this feature.
- Data Control Tower for Self-Service Users: The Data Control Tower Developer Experience is the successor to Continuous Data Self-Service. We’ve introduced the ability to lock VDBs and create point-in-time bookmarks to support your migration from Self-Service.
- UI-based Custom Hook Support: You now can add custom hooks to a VDB at provision time as part of the provision wizard UI and update them under a VDB’s detail page such that they will execute during refresh operations.
- Compliance Job Execution Metrics Report: A new report has been added to display all recent job executions, including Data Control Tower-initiated, engine-initiated, and hyperscale-initiated jobs and relevant compliance metrics.
Delphix Compliance Services
- Single Sign On (SSO): Customers can now authenticate on the Delphix Compliance Services Portal using their existing enterprise identity providers (IDP). The Delphix Compliance Services Portal is our customer-facing application that enables users to seamlessly import, configure, and manage their algorithms through an intuitive, self-service interface. PerforceID, the Perforce corporate IDP, is the underlying identity and access management layer.
- Dynamics365 Template: Delphix Compliance Services for Azure now provides pre-built pipelines for Microsoft Dynamics 365 environments using Dataverse as the underlying data platform. These pipelines automate the discovery and masking of sensitive data using Azure Data Factory (ADF).
Core Compliance Version Parity: Delphix Compliance Services is now using the latest versions of Automated Sensitive Data Discovery (ASDD) and Masking Plugins to bring the most advanced discovery capabilities and masking performance.
- ADLS Nested Directories Discovery: The Delphix Compliance Services pipeline now allows data profiling in more flexible directory structures on Azure Data Lake Storage (ADLS), enhancing speed and viability for sensitive data discovery in complex environments.
- Data Cleansing Algorithm: The Delphix Compliance Services framework now supports the DataCleansing algorithm to standardize spellings, misspellings, and abbreviations. This is a huge value add for analytics environments in combination with sensitive data masking.
- Azure MI Template: Out-of-the-box support for profiling and masking of Azure Managed Instance source and targets is now included with Delphix Compliance Services.
- Conditional Masking: Introduced a new option to conditionally apply masking algorithms based on a key column in Azure Dataflows
- Additional Templates: We've added templates for Azure Data Lake, CSV, and JSON and are continuing to release fast-start templates for the most requested data sources.
- Microsoft Fabric Beta: In conjunction with our feature at the Microsoft Fabric Community Conference, we have a beta offering (demoed at the conference) that allows you to find and mask data in the newest version of Microsoft Fabric dataflows.
- Quick-Start Templates: In the fall, we launched the capability to manage metadata as parameters and rapidly deploy masking across thousands of tables in a single Azure Data Factory (ADF) pipeline. To facilitate the fastest deployment for common data sources, we’re releasing parameterized templates for Snowflake and Databricks.
- Private Link for ASDD: Private Link is now supported for ASDD pipelines (in addition to masking pipelines). This lets you ensure that data sent to Delphix Compliance Services for Azure for profiling only moves within your virtual private network and never traverses the public internet.
- Data Flow Parameterization: In collaboration with Microsoft, it is now easier to rapidly deploy masking across thousands of tables in a single Azure Data Factory (ADF) pipeline, letting users manage relevant metadata as parameters. We’re releasing templates to expedite the deployment process for common data sources, starting with Snowflake.
- (Beta) Automatic Sensitive Data Discovery as a Service: This beta offering will allow you to profile and mask data in a single Azure Data Factory pipeline or split these into two separate pipelines depending on the desired review workflow. If interested, please contact [email protected].
- Support for Azure Private Link: You can now access Delphix Compliance Services for Azure over a private endpoint in your virtual network, avoiding exposure to the public internet.
- (Beta) Automatic Sensitive Data Discovery as a Service: This beta offering will allow you to profile and mask data in a single Azure Data Factory pipeline or split these into two separate pipelines depending on the desired review workflow. If interested, please contact [email protected].
Hyperscale Compliance
- Hyperscale Compliance on Data Control Tower for Oracle (Early Access): Data Control Tower now includes an integrated user interface for managing Hyperscale Compliance workflows for Oracle databases. Users can configure and execute Hyperscale masking jobs, monitor orchestrator flows, and track job execution and status, all from within Data Control Tower, without needing to interact with Hyperscale directly.
- This release brings together orchestrator flow management, job creation and monitoring, and real-time execution tracking into a unified Data Control Tower experience, with algorithm synchronization across Hyperscale nodes handled automatically in the background.
- To participate in the Early Access program, please contact [email protected]
- OpenShift Certified: Containerized masking engines is now fully certified to work with Hyperscale on Red Hat OpenShift environments. This milestone unlocks enterprise-scale data masking deployments for customers running containerized Hyperscale Compliance workloads on OpenShift, with full confidence in a tested and supported configuration.
- MongoDB Closed Appliance: Hyperscale Compliance for MongoDB can now be deployed as a VM Appliance for file and database masking. Packaged alongside existing Oracle and SQL Server closed appliance support, customers can select their MongoDB connector and begin masking without deploying or managing Kubernetes infrastructure.
- Unified Sensitive Data Discovery for Snowflake: Automated Sensitive Data Discovery (ASDD) Sync Support for Snowflake completes the end-to-end journey from discovery to masking across Continuous Compliance and Hyperscale Compliance. Customers can now profile Snowflake data using the standard ASDD experience and seamlessly apply those inventories to Hyperscale masking without custom scripting or heavy API usage. This also enables customers to retire the bespoke Hyperscale-only Snowflake profiler in favor of a unified workflow.
- Role-Based Authentication for S3-Compatible File Masking: The Hyperscale File Connector now supports role-based access for S3-compatible storage, including AWS IRSA, enabling secure, cloud-native authentication without managing long-lived credentials.
- VM Appliance for SQL Server: We’ve expanded the closed VM appliance form factor for Hyperscale Compliance to include Microsoft SQL Server in addition to Oracle. Both connectors are packaged together, allowing you to select your preferred connector during installation. You can switch between Oracle and MSSQL as needed, with one active connector at a time for streamlined operations.
- AWS S3 Staging: The Hyperscale File Connector now supports AWS S3 staging, giving customers flexibility to use cloud-hosted object storage for file masking workflows.
- NetApp S3-Compatible Connectivity: The Hyperscale File Connector now supports NetApp S3-compatible connectivity for both source and target, enabling direct ingestion and delivery of files from S3 repositories for streamlined masking workflows.
- VM Appliance (for Oracle): We’ve made it easier to deploy Hyperscale Compliance by packaging it as an OVA image for Oracle environments. This approach simplifies installation and sets the stage for adding all Hyperscale data sources in future releases. Container-based deployments remain supported for Oracle as well as all other data sources.
- Enhanced MongoDB Profiler: Our independent MongoDB profiler, designed as a NoSQL alternative to Automated Sensitive Data Discovery (ASDD), now offers functional parity with ASDD’s best features. It includes data-level profiling, custom profile sets, and improved randomness for a stronger and more consistent discovery process.
- Oracle Post Load Performance Optimization: We’ve introduced a tunable performance enhancement for the Post Load step in Hyperscale job execution for Oracle environments. By creating indexes in parallel with constraints, the post-load phase runs faster, resulting in improved end-to-end job execution times. This is especially important for complex datasets with large index and constraint builds, where eliminating this bottleneck significantly accelerates job completion without compromising data integrity.
- Hadoop Enhancements: We have strengthened Hadoop support across our Compliance solutions to give you more flexibility and tighter alignment with your existing workflows.
- Profiling (Continuous Compliance): The engine can now profile files inside Hadoop using a Hive JDBC driver.
- Masking (Hyperscale Compliance): You can now mask data directly to Hive databases, not just HDFS.
- Sync (Continuous Compliance to Hyperscale): Hive-based compliance inventories can now be synced with the file connector.
Hadoop File Workflows: Two key improvements were delivered to Hadoop Hyperscale Compliance solution. First, support for direct Parquet masking allows files to be sent straight to the compliance engine without conversion to other formats, streamlining performance for large-scale workflows. Second, we’ve introduced automated HDFS active server discovery, eliminating manual IP updates and reducing downtime during active/standby failovers.
- Snowflake on Azure: Hyperscale Compliance now supports Snowflake deployments on Azure, extending our existing AWS coverage. This enhancement allows customers to mask data in Snowflake without consuming Snowflake compute - preserving cloud performance and cost efficiency while meeting compliance goals at scale.
- Streamlined Parquet Workflows: Hyperscale now supports direct Parquet file processing on compliance nodes - eliminating the need to convert Parquet files to CSV before masking. This enhancement improves performance, reduces storage overhead, and streamlines workflows for cloud-native datasets stored in formats like S3 or Azure Blob.
Snowflake on AWS S3: The Snowflake Hyperscale Connector delivers high-speed, cost-efficient masking for big data used in AI and analytics. By leveraging Snowflake Load/Unload and AWS S3, large datasets can be rapidly masked without increasing Snowflake compute costs. The new Snowflake Profiler automatically detects sensitive data, inventories key columns, and submits metadata to the DataSets API, streamlining compliance for AI/ML and analytics pipelines.
- File Connector Enhancements - Parameters such as writer type, spark configuration settings, and max worker threads for each Hyperscale file connector job can now be configured without restarting your containers. You also can now apply different settings in parallel because variables are job and not container specific. See Kubernetes and OpenShift documentation to configure the source and target connector types.
- File Connector "Staging Push": Introduced feature that allows users to bypass the unload and load processing steps. This allows users to directly provide source files at a mount point mapped to the staging area. Instead of using writers to parse the source files during unload, a link to the files is created within the staging area and passed to the Continuous Compliance engine. During the load operation, the masked files will be available as links in the target location. Note, the staging push feature is restricted to delimited files.
- Oracle Dataset Filtering: You can now filter the source data to be processed by a Hyperscale job by applying a "where clause" filter condition in a job's data set. The "where clause" condition is added in unload SQL queries when fetching the data from a source database.
- Multiple Date Formats for MSSQL Connector: Provides the ability to automatically handle multiple date formats within a single job. This removes the limitation from jobs that require all date/timestamp columns in the dataset to have the same date formats.
- AWS S3 as a Staging Area: Adds the ability to use AWS S3 buckets as a staging area for Hyperscale Compliance. Note this feature is only available for Kubernetes deployment mode.
- Unload Split Calculation: An automatic calculation of unload split for Oracle DataSource has been added to eliminate the need to manually provide the number of splits. This not only saves time, but also makes the product more user-friendly and scalable.
- Kubernetes Deployment Configurations: Users can now specify resource requests and limits for a Kubernetes deployment.
- Hadoop: Hadoop Distributed File System (HDFS) data sources are now supported by Hyperscale Compliance.
- Delimited and Parquet Files: The Delimited and Parquet File Connectors are now consolidated into a single File Connector to simplify implementation configurations.
- Oracle Date Formats: We have introduced a feature that automatically handles multiple date formats within a single job. This removes the limitation from jobs that required all date/timestamp columns in the dataset to have the same date formats. Also starting this release, you no longer need to configure any unload/load date format environment variables to mask date/timestamp columns.
- MS SQL: We have made important improvements to both the unload and load processes, including the addition of date and time filtering on the unload and connection pooling on the load.
- Automated handling of Microsoft SQL Server partitioned indexes: Hyperscale now automates the handling of partitioned indexes (clustered and non-clustered), ensuring that partition indexes are dropped before load starts and created again once data is loaded back into the target database, saving users scripting time as well as improving overall job performance.
- Handling of WARNING status for Continuous Compliance Jobs: Hyperscale Compliance now handles a new job status. The behavior of Hyperscale Jobs with Continuous Compliance jobs in the new WARNING status is controlled via a flag added to the Hyperscale Job configurations. For configuration details and examples, refer to the Jobs API section on How to setup a Hyperscale Compliance job page.
- Automated handling of Oracle BLOB/CLOB Columns: Users now save time by automating the handling of Oracle BLOB/CLOB columns, ensuring that null or empty string values are managed seamlessly.
- Automated configuration of mount filesystem: New time-saving configuration settings enable the automatic configuration of the mount filesystem during application startup.
- MongoDB connector security enhancements: The MongoDB Hyperscale connector now supports Reduced Privilege Operations.
- Deployment platform certifications: Hyperscale Compliance now runs on AWS EKS for the Parquet and Delimited connectors and OpenShift for the MongoDB connector.
- MongoDB Connector Enhancements: Any Hyperscale MongoDB job, including the active unload, masking, and load tasks, can now be canceled while in process. The MongoDB connector can now generate a support bundle through APIs, like the existing feature for Oracle and MSSQL. The generated bundle will only have information on the controller and masking services for the Delimited and Parquet connectors.
- Deployment platform certifications: We have certified both the Oracle and MSSQL connectors on Amazon Elastic Kubernetes Service (EKS).
- AWS S3: We now support AWS S3 as a source and target location for the Delimited connector, in addition to the existing support for mounted filesystems (FS).
- Support Bundle APIs: Technical support bundles can now be efficiently generated asynchronously through APIs for Oracle and MSSQL connectors. For more information, refer to How to generate a support bundle.
- Import Masking Jobs: The job sync function has been improved to import jobs with rulesets containing structured data applied to data columns. A structuredDataFormats connector and a dataset are ready for immediate use upon import.
- OpenShift Support: Hyperscale Compliance can now be installed and hosted on an OpenShift cluster for Oracle, MSSQL, Parquet, and Delimited Connector data sources. In addition, multiple customization options have been added to leverage persistent volumes.
- NFS Support for Parquet: The Parquet connector now supports using local storage as both a source and target for Parquet files.
- Sharding support for MongoDB: The MongoDB connector now supports sharded MongoDB databases.
- Parquet Support: Hyperscale Compliance now supports masking Parquet files. Note that the Hyperscale Orchestrater must be sized correctly to handle Parquet files.
- Embedded XML/JSON: Applications increasingly store state as semi-structured data. To better cover these cases, masking XML and JSON content embedded in delimited files is now supported.
- Hyperscale UI in Data Control Tower: Hyperscale Compliance users can now leverage the Hyperscale User Interface in Data Control Tower to manage hyperscale orchestrators, manage and execute hyperscale jobs, and monitor job progress.
- MongoDB: MongoDB databases can now be masked with Hyperscale Compliance with horizontal-scale speed.
- Delimited Files Connector: You can now use Hyperscale Compliance to mask collections of delimited files of your choice. This connector allows you to bring the horizontal, high-speed masking of Hyperscale Compliance to data outside of end-to-end supported database types.
End-of-Life (EOL) Products
View the Delphix product EOL schedules:
- Continuous Data Oracle LiveSource
- Continuous Data and Continuous Compliance
- Data Control Tower
- Hyperscale Compliance
- Data Connectors
Continuous Data Oracle LiveSource EOL: We had previously announced the deprecation of Oracle LiveSource in July 2024. Continuous Data 2025.2 will be the last release with support for Oracle LiveSource and will be fully removed in 2025.3.
Data Control Tower External Postgres Database End of Support: PostgreSQL 12 and 13 are no longer supported as an external database version for Data Control Tower. Please upgrade to a supported external database PostgreSQL version before upgrading to Data Control Tower 2026.1.
Oracle move-to-asm.sh End of Support: The move-to-asm.sh scripted procedure has reached end of support in this release. To export an Oracle virtual DB or virtual PDB to a physical Oracle ASM or Exadata database, refer to perform the V2P operation on an Oracle VDB or vPDB to a Physical ASM or Exadata Database.
- Delphix Self-Service End of Life: The Self-Service (aka JetStream) UI, API, and CLI have been removed from releases 2025.6 and greater including the equivalent dxtoolkit commands. To avoid any unintentional loss, the engine will not proceed with the upgrade if there is any Self-Service configuration. Please migrate to Data Control Tower to adopt the next generation of Self-Service experiences. Standard support of legacy Continuous Data versions will continue to be available, however no patches or bug fixes will be provided. Please see our Delphix End Support announcement for more information.
- DCT Legacy PostgreSQL End of Support: In the 2026.1 release, we will end support for the PostgreSQL 12.x and 13.x database versions. Only Kubernetes or OpenShift installations that use the external database capability with one of these legacy versions are impacted. We encourage affected deployments to upgrade to PostgreSQL v14.x or v15.x before upgrading to 2026.1.
Final Delphix Self-Service (Jet Stream) Release: As part of our end-of-support plans, Continuous Data 2025.5 will be the last release with Delphix Self-Service (Jet Stream). The Delphix Self-Service interface, APIs, and dxtoolkit commands will be removed with Continuous Data 2025.6. All customers who wish to continue using Self Service should migrate to Data Control Tower immediately. Continuous Data 2025.6 upgrades will be blocked until your Delphix Self Service configuration has been migrated to Data Control Tower or removed. Please contact your Delphix Account Team for guidance.
- Delphix Self-Service (Jet Stream) Unavailable on New Installs: As part of our end-of-support plans, we have restricted the Delphix Self-Service feature in fresh installations of Delphix Continuous Data 2025.2 and greater. Upgrades are unaffected. The Delphix Self-Service interface and APIs will be removed from the product in 2025.6. Please contact your Delphix Account Team for guidance on how to migrate to Data Control Tower’s Developer Experience.
- End of Support for Older Databases and Environments: We have announced End of Support dates for various older databases (MongoDB, MySQL, PostgreSQL, and SAP HANA) and environments (AIX, SUSE, and Ubuntu). Please see the Delphix Community announcement for complete details.
- The Delphix Community is moving to Perforce Community Groups: On July 31, 2025, we will decommission the Delphix Community and transition to Perforce Community Groups. After this date, you will no longer be able to post in the Delphix Community. But don’t worry — we have designed the Perforce Community Groups to give you an even better, more unified space to discuss Delphix and other Perforce products and services. Watch this short video to learn how to access the new Delphix and Perforce Community Groups.
- Delphix Self-Service (Jet Stream) Unavailable on New Installs: As part of our end-of-support plans, we have restricted the Delphix Self-Service feature in fresh installations of Delphix Continuous Data 2025.2 and greater. Upgrades are unaffected. The Delphix Self-Service interface and APIs will be removed from the product in 2025.6. Please contact your Delphix Account Team for guidance on how to migrate to Data Control Tower’s Developer Experience.
- End of Support for Older Databases and Environments: We have announced End of Support dates for various older databases (MongoDB, MySQL, PostgreSQL, and SAP HANA) and environments (AIX, SUSE, and Ubuntu). Please see the Delphix Community announcement for complete details.
- Oracle LiveSource EOL: Starting with the May 2025.3 release, Oracle LiveSource is fully removed from the product line and no longer supported.
- End of Support for Data Control Tower on Docker Compose:
Documentation Updates
We have made centralization improvements to the Continuous Data Connector documentation to ease discovery and re-use as users adopt Data Control Tower. Going forward, all Continuous Data Connector documentation can be found in the Ecosystem Hub documentation. In new documentation versions, you will find appropriate redirects from the core Data Control Tower and Continuous Data documentation to their new locations.
AI Services in Delphix, Powered by Perforce Intelligence
AI services, powered by Perforce Intelligence, optionally embed a supported language model into Data Control Tower Enterprise (read the Data Control Tower release updates below for the full details). In the July 2025 release, Perforce Intelligence introduces AI-powered synthetic algorithms that remove the manual, error-prone process of building secure lookup lists by leveraging language models that automatically generate synthetic lists.

Download Delphix Releases
Visit the Delphix downloads site to get the latest releases of your products.
Visit Delphix Community
Engage, learn, and network with your peers and Delphix experts in the new Perforce Community Groups.